
📒 学霸笔记:06|上下文的艺术(上):详解 CLAUDE.md 与 AGENTS.md
Top Student Notes: 06 | The Art of Context (Part 1): Understanding CLAUDE.md and AGENTS.md
课程 / Course: AI 原生开发工作流实战 / AI-Native Development Workflow in Practice
讲师 / Instructor: Tony Bai
章节 / Chapter: 06
主题 / Topic: AI Agent 的长期记忆、CLAUDE.md、AGENTS.md、分层上下文、导入语法、生命周期管理
一、这一讲在回答什么问题?
What Problem Does This Lecture Solve?
上一讲我们学会了:
@:把文件或目录作为上下文喂给 AI!:让 AI 执行 shell 命令并进入工作流
但很快就会遇到一个新痛点:
有些信息你不是“这次要告诉 AI”,而是“每次都想让 AI 记住”。
例如:
- 错误处理必须用
errors.Is / errors.As - Commit Message 必须符合 Conventional Commits
- API 响应体必须遵循固定结构
- 测试优先使用表格驱动风格
- 日志必须带
traceID
如果你每次开新会话都重复输入这些规则,效率会非常低。
所以这一讲解决的是:
如何给 AI 构建“长期记忆系统”,让它从通用助手变成真正懂你项目的工程伙伴。
二、本讲核心结论
Core Conclusion of This Lecture
一句话总结
@解决“当前任务的短期上下文”,CLAUDE.md/AGENTS.md解决“跨任务、跨会话的长期上下文”。
三、短期记忆 vs 长期记忆
Short-Term Memory vs Long-Term Memory
这是本讲的第一个核心模型。
1. @ 是短期工作记忆
@ as Short-Term Working Memory
例如:
@main.go
表示:
- 当前对话聚焦于
main.go - 是一次性任务相关上下文
- 对话切换后不一定继续有效
- 任务完成后这个焦点可能自然消失
类比
像你对同事说:
“你看一下这个文件。”
2. CLAUDE.md / AGENTS.md 是长期记忆
CLAUDE.md / AGENTS.md as Long-Term Memory
它们用于沉淀:
- 高频规则
- 项目约束
- 团队共识
- 架构准则
- AI 行为规范
这些内容在会话开始时自动加载,成为 AI 的“背景知识”。
类比
像你们团队有一本:
《团队开发规范手册》
而你的同事已经把它内化成了工作习惯。
3. 最关键的区别
| 维度 | @ |
CLAUDE.md / AGENTS.md |
|---|---|---|
| 作用 | 一次性上下文 | 持久背景知识 |
| 生命周期 | 当前任务/当前会话 | 跨会话长期有效 |
| 用途 | 具体文件/目录聚焦 | 通用规则/稳定约束 |
| 类比 | “看一下这个” | “记住我们一直这样做” |
四、为什么需要长期记忆?
Why Do We Need Long-Term Memory?
Tony 认为,这不只是“少打几句话”的效率问题,而是:
人机协作模式的规范化与工程化
如果没有长期记忆,会发生什么?
- 你不断重复同样规则
- 每个会话都从零重新校准 AI
- 团队成员和 AI 协作风格不一致
- 规则无法沉淀为工程资产
- AI 的表现不稳定
有了长期记忆之后
- AI 在启动时自动带着项目规范工作
- 团队规范变成机器可执行约束
- 个人习惯与团队规则可以分层管理
- 协作一致性明显提升
- AI 更像“项目成员”而不是“外来顾问”
五、AGENTS.md:从项目私约到行业标准
AGENTS.md: From Project-Specific Contract to Industry Standard
这是本讲很重要的前瞻性部分。
1. 问题背景:巴别塔困境
The Babel Problem
不同 Agent 工具各自有自己的上下文文件:
- Claude Code →
CLAUDE.md - Gemini CLI →
GEMINI.md - CRUSH →
CRUSH.md - 未来可能还有更多
XX.md
这样就会产生一个新问题:
你不再需要复制粘贴上下文,
但你开始要维护多套 AI 配置文件。
这就是 Tony 所说的:
“巴别塔困境”
2. AGENTS.md 为什么出现?
它的目标是:
成为跨 Agent 的通用上下文标准
核心理念:
给 AI Agent 准备一份专属的、标准化的
README.md
也就是说:
README.md是写给人看的AGENTS.md是写给 AI Agent 看的
3. AGENTS.md 该写什么?
一个典型 AGENTS.md 会包含:
- 技术栈
- 本地运行方式
- 测试命令
- lint 命令
- Git / PR 规范
- 分支命名规则
- 质量门槛
它解决了什么?
它让 AI 一进项目就能知道:
- 这是什么项目
- 怎么运行
- 怎么验证
- 怎么提交
- 什么是被允许的团队协作格式
4. AGENTS.md 的战略意义
Tony 不是把它当作一个“新文件名”,而是把它视为:
AI 原生开发的行业通用协作协议
这和课程前面反复强调的思想一致:
学习通用方法论,而不是绑定某个工具的私有技巧。
六、CLAUDE.md 与 AGENTS.md 的关系
Relationship Between CLAUDE.md and AGENTS.md
这是本讲一个特别重要的实践结论。
当前现实情况
截至课程讲解时:
Claude Code 还没有明确原生支持自动发现
AGENTS.md
所以今天的最佳实践不是“二选一”,而是:
协同使用
最佳协同模式
1. AGENTS.md 作为公有契约
放那些:
- 通用的
- 跨 Agent 可理解的
- 不依赖特定工具能力的规则
例如:
- 技术栈
- 测试命令
- lint 命令
- Git 提交规范
- PR 命名规范
2. CLAUDE.md 作为私有扩展
放那些:
- Claude Code 专属
- 依赖 Claude 高级能力
- 与 Sub-agent / Hooks / Claude 交互方式相关的内容
例如:
- 调用某个 Sub-agent
- 编辑后自动运行
gofmt - Claude Code 特有工作流指令
一个非常实用的模式
在 CLAUDE.md 中导入 AGENTS.md:
@../AGENTS.md
然后在下面补充 Claude Code 专属能力。
学霸理解
这相当于:
AGENTS.md是底层通用协议CLAUDE.md是 Claude 平台适配层
七、深入 CLAUDE.md:为什么它强?
Why CLAUDE.md Is Powerful
Tony 认为它强,不只是因为“自动加载”,而是因为它有两个关键能力:
- 分层加载
- 模块化导入
八、CLAUDE.md 的分层加载机制
Layered Loading Mechanism of CLAUDE.md
这是本讲的核心中的核心。
1. 四级分层思想
Tony 把它理解为:
从“公司规定”到“团队规范”再到“个人习惯”的层级体系
虽然课程中还提到企业策略层与更高配置体系,但就 CLAUDE.md 的实操角度,最重要的是这几个层次:
- 企业级
- 项目级
- 用户级
- 子目录级(按需加载)
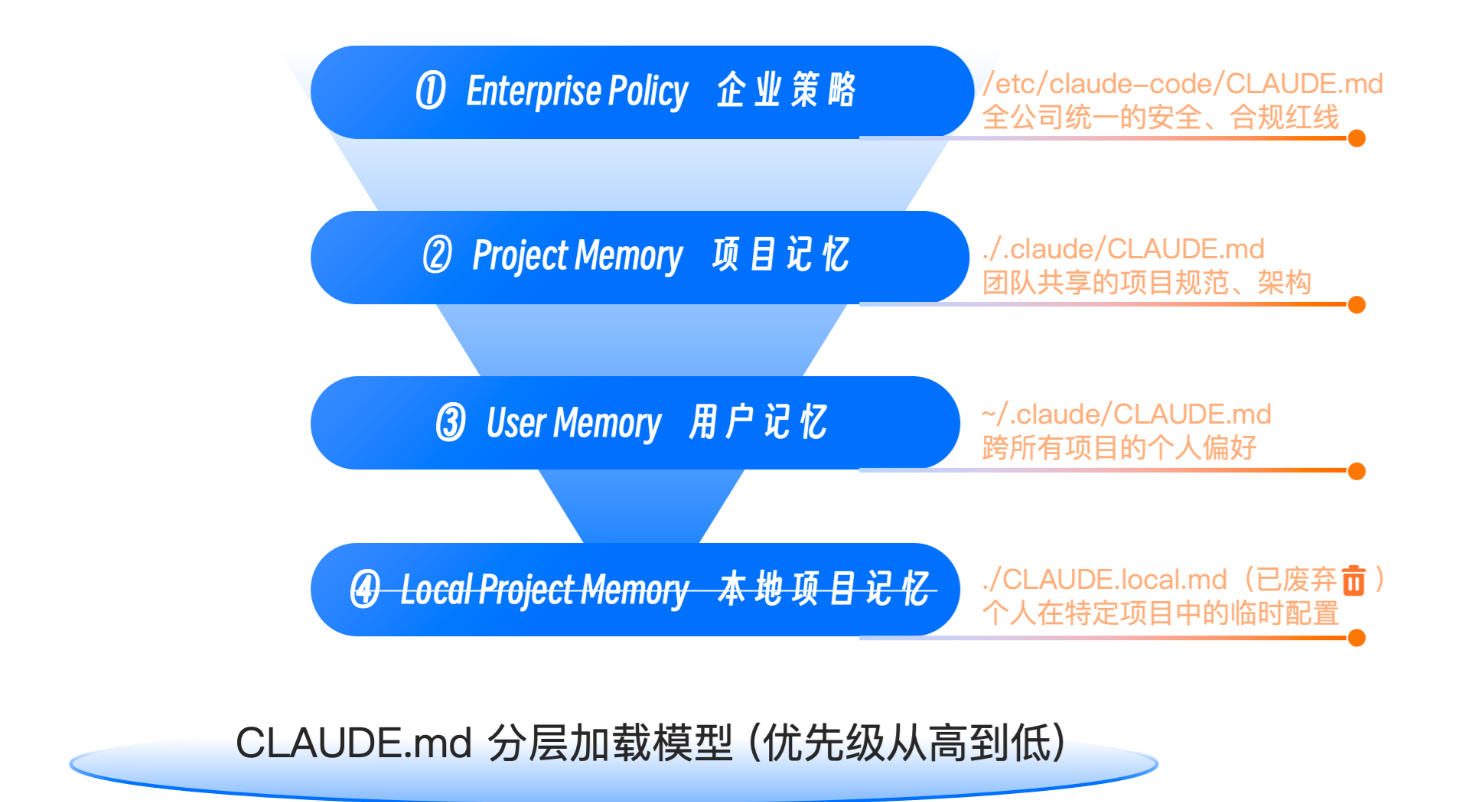
2. 核心原则
越上层越全局,越下层越具体;越具体的上下文离代码越近。
九、两个特别重要的机制:向上递归 + 向下动态发现
Two Crucial Mechanisms: Upward Recursion + Downward Dynamic Discovery
1. 向上递归查找
Recursive Upward Search
当你在某个目录启动 Claude Code 时,它会:
- 从当前目录开始
- 向上一级一级查找
- 直到项目根目录(通常
.git所在)或用户主目录 - 加载沿途遇到的所有
CLAUDE.md
这意味着什么?
如果你在 services/user-service/ 中启动 Claude:
- 项目根的全局规范会被加载
user-service自己的服务规范也会被加载
学霸理解
这是一种 级联上下文模型(cascading context model)
2. 向下动态发现
Dynamic Downward Discovery
这是更精妙的机制。
Claude Code 不会在启动时把所有子目录的 CLAUDE.md 都加载进来。
而是:
只有当 AI 真正读取某个子目录下文件时,才动态加载该目录相关的
CLAUDE.md。
为什么这个设计很高级?
因为它做到了:
- 避免一次性加载整个 monorepo 的所有规则
- 节省 token
- 提高相关性
- 保持 AI 专注当前任务
学霸理解
这是:
按需加载上下文(Context on Demand)
十、Monorepo 场景如何理解?
How to Understand This in a Monorepo?
Tony 用 monorepo 举例特别好。
场景 1:在 user-service 目录启动
Claude Code 会自动加载:
- 根目录规范
user-service局部规范
这样 AI 从一开始就知道:
- 项目全局约束
- user-service 的专属业务规则
场景 2:在项目根目录启动,但读取 order-service 文件
Claude Code 启动时只加载根上下文。
当你后续执行:
@services/order-service/main.go
Claude 在读取该文件时,会再动态加载 order-service 专属上下文。
学霸一句话总结
Claude Code 的上下文机制 = 向上继承全局规范,向下按需激活局部规范。
十一、@ 导入语法:模块化上下文
@ Import Syntax: Modularizing Context
如果一个 CLAUDE.md 写得越来越大,维护会很痛苦。
所以 Claude Code 提供了 @ 导入语法,让你像管理代码模块一样管理上下文。
基本语法
@/path/to/another/file.md
支持:
- 相对路径
- 绝对路径
为什么它重要?
因为它让上下文可以:
- 拆分
- 复用
- 组合
- 分层组织
这意味着:
你不是在写一个大杂烩文档,而是在搭一个上下文模块系统。
实战模式 1:团队规范 + 个人偏好分离
例如:
项目级共享文件
./.claude/CLAUDE.md
放:
- 团队规则
- 架构约束
- 测试规范
- 提交流程
用户级个人文件
~/.claude/personal-preferences.md
放:
- 你偏好的编码风格
- 你喜欢的解释方式
- 你个人的默认工作习惯
然后在项目 CLAUDE.md 中导入:
@~/.claude/personal-preferences.md
学霸理解
这其实是在实现:
- 团队共识统一
- 个人风格可插拔
实战模式 2:按主题拆分
例如你可以维护:
golang-style.mdgit-workflow.mdwriting-style.md
然后在全局 ~/.claude/CLAUDE.md 中组合导入:
@~/.claude/contexts/golang-style.md
@~/.claude/contexts/git-workflow.md
@~/.claude/contexts/writing-style.md
学霸理解
这就像:
- 配置即模块
- 规则即依赖
- 上下文即可组合资产
十二、CLAUDE.md 的生命周期管理
Lifecycle Management of CLAUDE.md
Tony 把管理分成三个阶段:
- 创建
- 追加
- 系统性修改
1. /init:从 0 到 1 创建
/init: Create from Scratch
适用场景:
- 新项目
- 老项目首次接入 Claude Code
- 不知道该怎么开始写
执行 /init 后,Claude Code 会:
- 扫描项目
- 识别技术栈、主要文件、构建方式
- 自动生成一个带标准结构的
CLAUDE.md
/init 的哲学
最佳实践引导(Scaffolding / Bootstrap)
它不是替你完成最终版本,而是:
- 帮你建立一个合理起点
- 降低第一次写配置的心理门槛
- 避免结构从一开始就混乱
2. #(历史上)/ 自然语言记忆更新:即时追加
Instant Append
课程里提到一个版本变化:
近期 Claude Code 已移除
#快捷指令
现在可以用自然语言或/memory达到类似效果
历史上的 # 作用是:
- 当场记下一条规则
- 选择写入哪个
CLAUDE.md - 即时沉淀刚刚在对话中发现的规范
这类机制的哲学
把灵感即时沉淀成规则
也就是:
- 从“口头提醒”变成“工程规范”
- 从“临时提示”变成“可复用资产”
3. /memory:系统性维护
/memory: Systematic Maintenance
适用场景:
- 重构整个文件
- 删除过期规则
- 调整组织结构
- 大规模修改上下文内容
特点:
- 自动列出可编辑的
CLAUDE.md - 用系统默认编辑器打开
- 保存后自动重新加载
- 修改立即生效
/memory 的哲学
像整理书架一样维护你的长期记忆系统
十三、如何写一份高质量 CLAUDE.md
How to Write a High-Quality CLAUDE.md
Tony 最有价值的部分之一,是给出了一个 Go 项目通用模板,并解释“为什么这样写”。
这里最重要的不是照抄,而是理解其结构设计。
十四、高质量 CLAUDE.md 的五大组成部分
The Five Main Sections of a High-Quality CLAUDE.md
1. 角色设定 / Mission & Role
例如:
你是一位精通 Go 的资深工程师……
为什么重要?
这属于 角色扮演提示(Role Prompting)
它会引导 AI:
- 更偏向工程最佳实践
- 不只是给出能跑的代码
- 还要考虑维护性、扩展性和质量
2. 技术栈与环境
包括:
- Go 版本
- Web 框架
- ORM / 数据库
- 测试命令
- lint 命令
- 格式化工具
为什么重要?
因为它能防止 AI:
- 用错框架
- 猜错命令
- 给出与你项目不一致的实现方式
学霸理解
这部分是在 锚定 AI 的工程坐标系
3. 架构与代码规范
包括:
- 项目布局
- 错误处理方式
- 日志规范
- 接口设计原则
为什么重要?
因为这里是在给 AI 设定“硬约束”。
比如:
- 错误必须包装
- 必须用
slog - 业务逻辑放在
internal/
这能显著减少 AI 生成“貌似能跑、实际不合规范”的代码。
4. Git 与版本控制
例如:
- Conventional Commits
- 提交格式要求
为什么重要?
因为 AI 不只是帮你写代码,还会帮你:
- 写 commit message
- 整理 PR 描述
- 参与 Git 工作流
这一部分是在统一团队协作语言。
5. AI 协作指令
这是最“AI 原生”的部分。
包括:
- 优先标准库
- 先审查再编码
- 测试优先用表格驱动
- 涉及并发必须指出风险
- 复杂代码要解释设计意图
为什么这是最高级用法?
因为你不是在告诉 AI “项目是什么”,而是在:
直接编程 AI 的行为模式
这部分决定 AI 的工作方式,而不只是知识背景。
十五、从“文档”到“行为编程”
From Documentation to Behavioral Programming
这一讲一个非常高级的思想是:
CLAUDE.md不是普通文档,而是 AI Agent 的行为配置程序。
普通文档的作用
- 给人看
- 做说明
- 可选参考
CLAUDE.md 的作用
- 给 AI 看
- 形成行为约束
- 自动生效
- 影响执行路径
典型例子
文档式说法
“我们团队一般喜欢先看代码再动手。”
行为编程式说法
[流程] 当被要求实现一个新功能时,第一步必须先阅读相关代码,并以列表形式提出实现计划,待我确认后再开始编码。
学霸理解
后者已经不只是描述偏好,而是在定义:
- 触发条件
- 标准动作
- 审批节点
这本质上就是工作流编排。
十六、本讲的最大价值:把隐性知识显性化
The Biggest Value of This Lecture: Making Tacit Knowledge Explicit
Tony 在思考题里特别强调了一件事:
你团队里一定有很多“靠口口相传”的神秘规则。
例如:
- 用户 ID 绝不能直接暴露数据库自增 ID
- 某些接口必须走审计日志
- 某类业务逻辑必须包事务
- 某种错误不能直接返回给前端
- 某个目录禁止放业务代码
这些东西通常:
- 不写在 README
- 不写在编码规范
- 只在 Code Review 时被提醒
- 只靠老同事口耳相传
CLAUDE.md 的真正意义
就是把这些隐性知识变成:
- 可写下来的规则
- 可共享的团队资产
- 可被 AI 执行的工程约束
一句话
CLAUDE.md是团队工程文化的代码化沉淀。
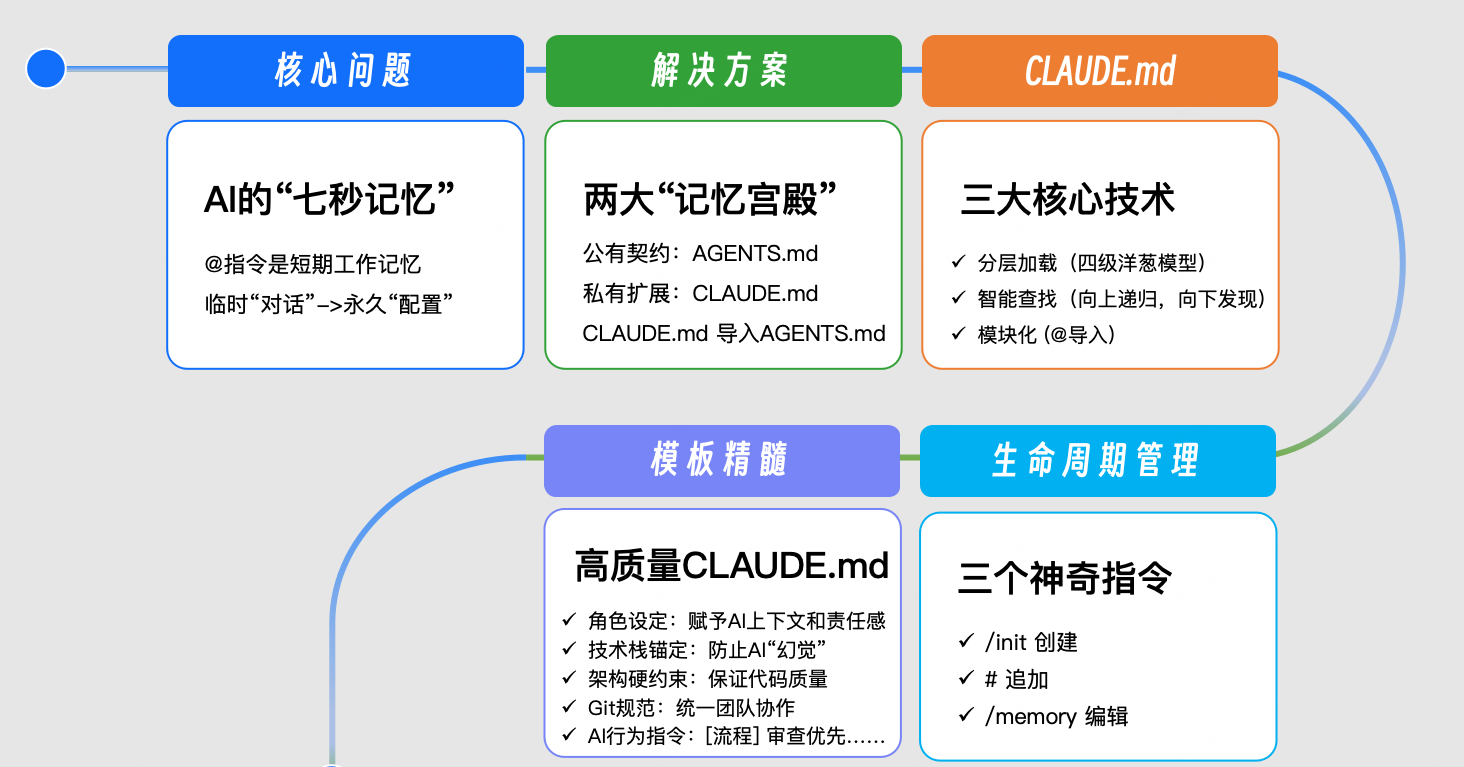
十七、这一讲的知识结构图
Knowledge Structure of This Lecture
短期上下文:@
↓
长期上下文需求出现
↓
需要长期记忆系统
↓
AGENTS.md:跨 Agent 通用标准
CLAUDE.md:Claude Code 私有强能力上下文
↓
二者协同:
AGENTS.md 做公有契约
CLAUDE.md 做私有扩展
↓
CLAUDE.md 的能力:
- 分层加载
- 向上递归
- 向下按需发现
- @ 模块化导入
- /init 创建
- /memory 维护
↓
最终目标:
把团队隐性知识工程化、资产化、可执行化
十八、学霸速记表
Quick Revision Table
| 知识点 | 结论 |
|---|---|
@ 是什么? |
短期工作记忆,解决当前任务上下文 |
CLAUDE.md 是什么? |
Claude Code 的长期上下文机制 |
AGENTS.md 是什么? |
面向未来的跨 Agent 通用标准 |
| 为什么需要长期记忆? | 避免重复提示,沉淀团队规则,提高一致性 |
CLAUDE.md 和 AGENTS.md 的关系 |
前者私有扩展,后者公有契约,协同使用 |
CLAUDE.md 的核心能力 |
分层加载 + 模块导入 |
| 向上递归查找 | 加载当前目录到项目根路径上的上下文 |
| 向下动态发现 | 只有读取子目录文件时才加载其局部上下文 |
@ 导入语法的作用 |
模块化、复用、组合上下文 |
/init |
生成第一版上下文模板 |
/memory |
系统性编辑和维护上下文 |
高质量 CLAUDE.md 的本质 |
不是文档,而是 AI 的行为配置程序 |
十九、学霸自检题
Self-Check Questions
基础题
@和CLAUDE.md分别对应什么类型的记忆?- 为什么
AGENTS.md会被视为一种行业标准趋势? CLAUDE.md与AGENTS.md的最佳协作方式是什么?
进阶题
- Claude Code 的“向上递归 + 向下动态发现”机制有什么工程价值?
- 为什么说
CLAUDE.md的@导入语法使上下文具备了模块化能力? /init、/memory分别适合用在什么场景?
思辨题
- 你团队中有哪些“老同事都知道、新同事总踩坑”的隐性规则?
- 你是否能把这些规则翻译成
CLAUDE.md中可执行、无歧义的指令? - 如果你的项目是 monorepo,你会如何设计根目录、服务目录、个人目录三层上下文?
二十、学霸总结
Top-Student Summary
这一讲真正讲的不是两个文件名,而是:
如何为 AI Agent 构建长期、分层、可维护的上下文系统。
其中:
@负责短期工作记忆CLAUDE.md负责 Claude Code 的长期记忆AGENTS.md代表跨 Agent 的未来标准
AGENTS.md 的意义在于打破不同 Agent 各自定义私有上下文文件所造成的碎片化,让 AI 协作规范有机会变成行业共识。
而 CLAUDE.md 则是当前 Claude Code 生态里最强大、最成熟的上下文机制,它通过:
- 分层加载
- 向上递归
- 向下动态发现
@模块导入/init初始化/memory维护
共同构成了一套真正工程化的 AI 长期记忆系统。
更重要的是,CLAUDE.md 的价值不只是“记录规则”,而是把团队中那些靠口口相传、Code Review 时反复提醒的隐性知识,转化为 AI 可理解、可执行的明确约束。
所以它不是普通文档,而是:
团队工程文化和协作规范的代码化表达。
二十一、一句话记忆
One-Sentence Memory Hook
@让 AI 记住眼前的事,CLAUDE.md/AGENTS.md让 AI 养成长期的工程习惯。