
📒 学霸笔记:09|安全基石(上):用权限控制与沙箱为 AI 戴上“安全镣铐”
Top Student Notes: 09 | Security Foundations (Part 1): Putting “Safety Shackles” on AI with Permissions and Sandboxing
课程 / Course: AI 原生开发工作流实战 / AI-Native Development Workflow in Practice
讲师 / Instructor: Tony Bai
章节 / Chapter: 09
主题 / Topic: Claude Code 安全模型、Permissions、Sandbox、默认不信任、最小权限、Bash 风险控制、安全 YOLO 模式
一、这一讲在解决什么问题?
What Problem Does This Lecture Solve?
前 8 讲,我们一直在给 AI 加能力:
- 给它眼睛:
@ - 给它手脚:
! - 给它长期记忆:
CLAUDE.md - 给它原则约束:
constitution.md - 给它快捷工作流:Slash Commands
但能力越强,风险越高。
于是问题来了:
你真的敢让 AI 在你的电脑里读文件、改代码、跑命令吗?
这不是“技术小问题”,而是 AI 原生开发能否真正落地的关键门槛。
因为一旦没有安全边界,AI 的风险非常现实:
- 误执行危险命令
- 读取敏感文件
- 泄露凭据
- 修改关键配置
- 越权访问网络
- 在你没意识到时造成破坏
所以这一讲的目标很明确:
建立对 AI Agent 的技术性信任,不靠“它很聪明”,而靠“它即使犯错,也伤不到你”。
二、本讲核心结论
Core Conclusion of This Lecture
一句话总结
对 AI 的信任,不能建立在主观乐观上,而必须建立在“权限体系 + 沙箱机制”这套客观安全边界上。
三、AI Agent 的核心风险到底是什么?
What Is the Core Risk of an AI Agent?
Tony 特别强调:
AI 的风险不主要来自“恶意”,而主要来自“不确定性”和“意图偏差”。
这点非常重要。
1. 指令的模糊性
Ambiguity of Human Instructions
人类说话常常是模糊的。
例如:
- “清理一下”
- “上线吧”
- “处理掉这些临时文件”
- “顺手修一下”
人类同事会自动补全大量隐含上下文。
但 AI 不一定。
它可能做最字面的理解。
于是“清理一下”可能走向危险操作。
2. 上下文永远不完整
Context Is Always Incomplete
即使你用了 @、CLAUDE.md、constitution.md,AI 看到的世界仍然是局部的。
它可能知道:
- 要改这个文件
但不知道:
- 这个文件正被关键服务依赖
- 这行配置是线上系统的“保险丝”
- 这个脚本在生产环境有副作用
所以 AI 的决策常常建立在“不完整世界模型”上。
3. 大模型有统计随机性
Statistical Randomness of LLMs
LLM 本质是概率生成系统。
同样输入,不同时间也可能略有差异。
这带来创造力,也带来:
- 不稳定性
- 不可完全预测性
- 边界模糊
学霸理解
这一讲最根本的思想是:
AI 风险的本质不是“坏”,而是“聪明但不可靠”。
所以安全设计不能靠“信它”,而要靠:
限制它、隔离它、监督它。
四、Claude Code 的安全哲学
Claude Code’s Security Philosophy
Tony 总结成一句非常重要的话:
默认不信任,逐步授权,全程监督。
这是整讲的主心骨。
1. 默认不信任
不要预设:
- AI 能理解你的隐含意图
- AI 不会越界
- AI 会自动分辨风险大小
默认假设它可能出错。
2. 逐步授权
AI 不是一开始就拿到所有权限。
而是:
- 从最小权限开始
- 只对必要动作授权
- 可按命令、按工具、按场景细分
3. 全程监督
人始终拥有最终主权:
- 可以单次批准
- 可以统一配置
- 可以查看当前规则
- 可以加强或收紧权限
五、安全模型的两大支柱
The Two Pillars of the Security Model
这一讲的主体内容就是这两部分:
- 权限体系(Permissions)
- 沙箱机制(Sandboxing)
它们不是二选一,而是互补关系。
权限体系是什么?
像:
应用层面的法律
它规定:
- 什么能做
- 什么不能做
- 什么必须问你
沙箱机制是什么?
像:
操作系统层面的监狱 / 物理隔离区
它不是讲规则,而是直接从 OS 层面限制:
- 文件系统访问
- 网络访问
- Bash 命令边界
一句话
Permissions 管“应不应该做”,Sandbox 管“就算做错了也做不到多坏”。
六、第一大支柱:权限体系
Pillar One: Permissions
权限体系是 Claude Code 安全模型的第一道核心防线。
Tony 说得很到位:
这是一套“宏观模式 + 微观规则”的授权系统。
七、权限设计的三大原则
Three Design Principles of Permissions
1. 默认最小权限
Least Privilege by Default
默认情况下,AI 更像“只能看、不能乱动”的顾问。
这意味着系统倾向于:
- 不默认放开高风险操作
- 把危险权限关得很紧
2. 显式授权
Explicit Authorization
任何改变系统状态的操作,例如:
- 改文件
- 写文件
- 执行 shell
- 调依赖
- 提交 Git
都应该在规则里明确说明。
3. 用户主权
User Sovereignty
最终控制权属于用户,不属于 AI。
你可以:
- 每次都确认
- 对安全动作自动放行
- 对高危动作永远拒绝
- 对不确定动作设置询问
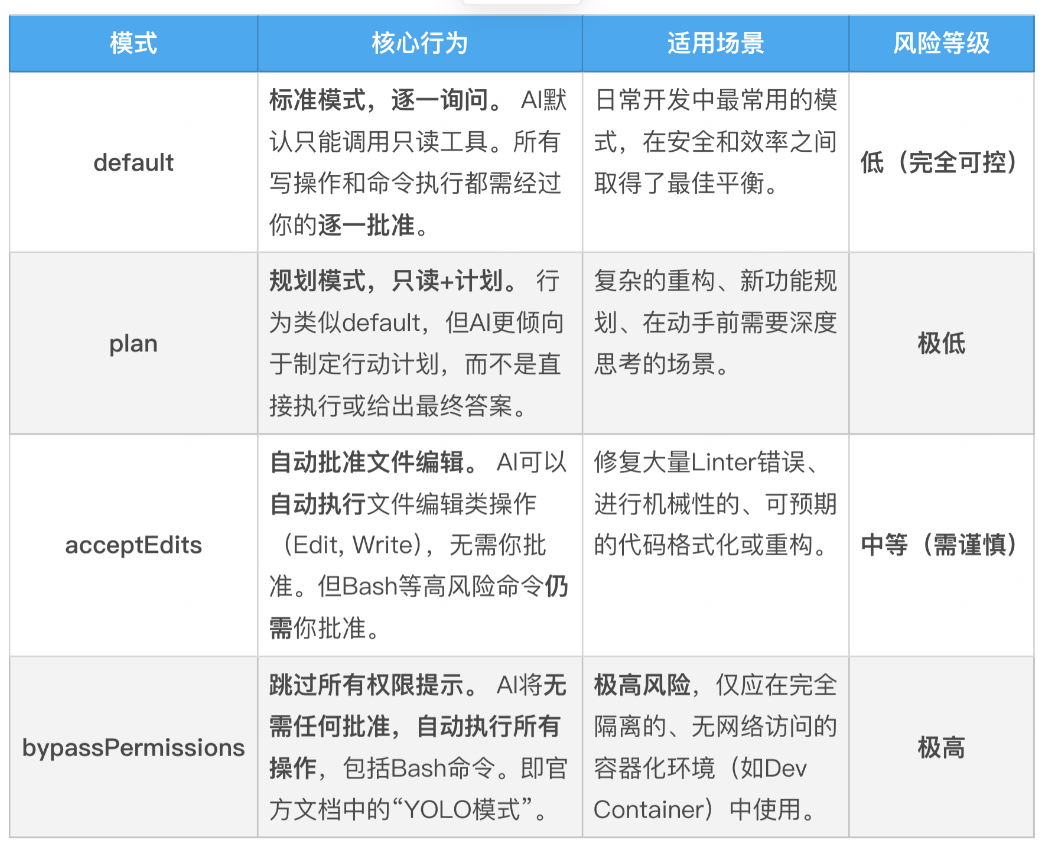
八、宏观控制:四大权限模式
Macro Control: Four Permission Modes
Claude Code 提供四种预设模式,用来快速切换整体信任级别。
虽然课文截图没有把四种都完整展开文字说明,但 Tony 特别强调:
default模式最常用,因为它在安全和效率之间取得了最佳平衡。
理解方式
你可以把“模式”理解为:
整体信任基调
例如:
- 有的模式偏保守,只给计划不给执行
- 有的模式偏高效,会更积极接受改动
- 有的模式偏自动化,但风险更高
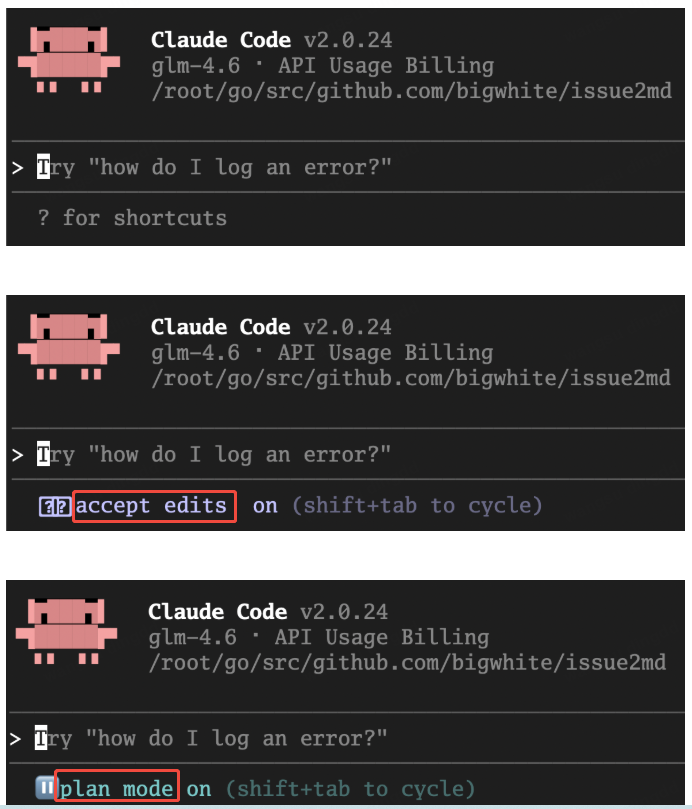
切换操作
通过 Shift+Tab 快捷键在启动的 Claude Code 会话中循环,在 default、plan 和 acceptEdits 模式间切换:
学霸记忆点
模式负责“宏观气候”,规则负责“具体法律”。
九、微观控制:权限规则
Micro Control: Permission Rules
这才是权限体系真正的精髓。
通过 settings.json 里的规则,你可以像立法一样规定:
allowdenyask
十、规则优先级
Rule Priority
Tony 特别提醒了规则决策顺序:
deny最高优先,其次allow,最后才是ask和默认模式行为。
这个顺序必须记住。
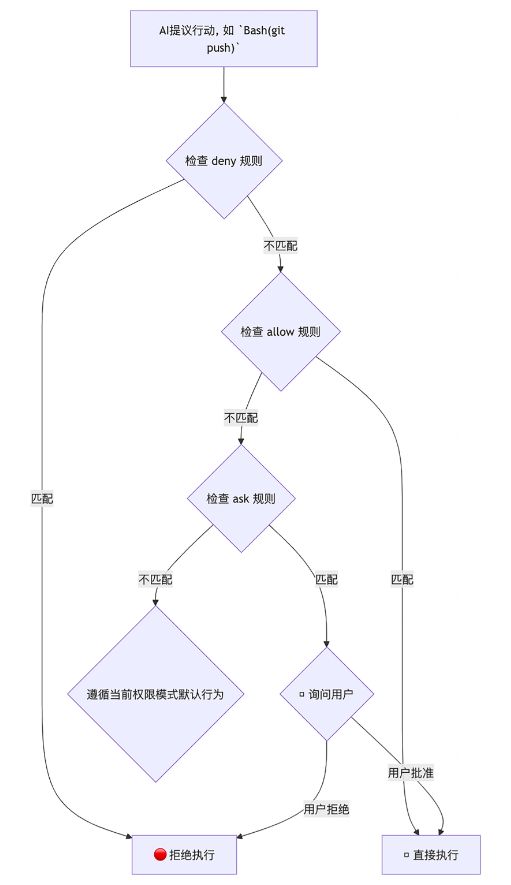
口诀
先看禁令,再看绿灯,最后才看要不要问。
十一、规则是分层生效的
Rules Are Layered by Scope
settings.json 可以有多个层级:
- 企业级
- 用户级
- 项目级
遵循原则:
高优先级覆盖低优先级
这意味着什么?
你可以:
项目级
给团队统一配置
- 哪些命令安全
- 哪些文件敏感
- 哪些操作必须审批
用户级
给自己再加一层更严约束
- 进一步收紧权限
- 加上个人机器敏感路径保护
学霸理解
这和很多配置系统一样,是一种:
层次化治理模型
既支持团队规范,又保留个人主权。
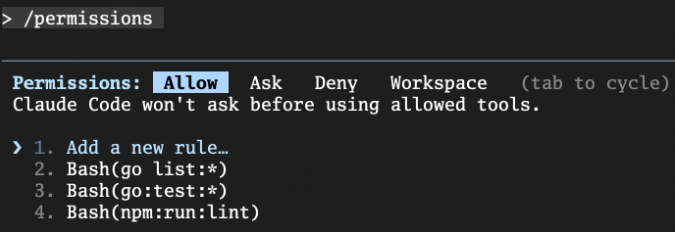
十二、如何查看当前生效规则?
How to Inspect Effective Rules?
答案是:
/permissions
这个命令非常重要。
为什么重要?
因为权限配置一旦复杂,你最怕两件事:
- 规则没生效
- 规则和你以为的不一样
/permissions 就是:
权限配置的调试面板
它会告诉你当前:
- 哪些规则正在生效
- allow / deny / ask 各是什么
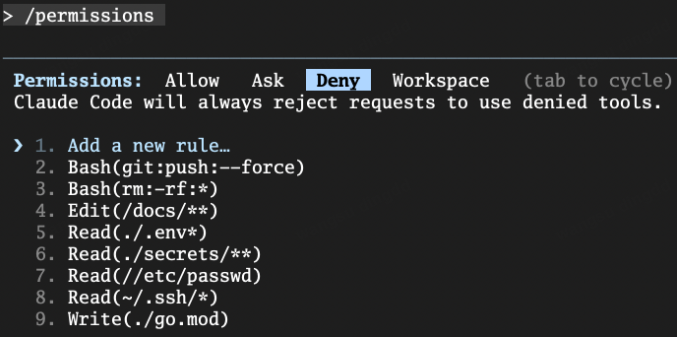
十三、文件权限控制:Read / Edit / Write
File Access Control: Read / Edit / Write
这是最基础也最关键的一类规则。
因为很多真正危险的事,不一定来自执行命令,而是来自:
- 读到不该读的秘密
- 改到不该改的核心文件
- 写坏关键配置
典型用途
Read
控制 AI 能不能读某些文件
适合保护:
.envsecrets/~/.ssh/- 系统敏感文件
Write
控制 AI 能不能直接写某些文件
适合保护:
go.mod- lockfile
- 核心配置
- 生成文件边界
Edit
控制 AI 能不能修改已有文件
适合限制:
- 文档目录
- 不希望 AI 动的模块
- 只读区域
十四、路径模式是本讲的细节点之一
Path Patterns Are an Important Detail
Tony 特别强调,这里非常容易搞错。
1. path 或 ./path
相对于当前工作目录
例如:
Read(./.env*)
2. /path
相对于 settings.json 所在目录
这点很容易误判。
在项目级 ./.claude/settings.json 中:
Read(/config/**)
指的是项目根目录下的 config/
3. ~/path
相对于用户主目录
例如:
Read(~/.ssh/**)
4. //path
文件系统绝对路径
例如:
Read(//etc/passwd)
学霸提醒
这个双斜杠 // 很关键。
别把绝对路径和相对路径规则混掉。
十五、Bash 权限控制:风险最高的一类
Bash Permissions: The Highest-Risk Category
Tony 说得很明确:
Bash 是 AI 最强的武器,也是最危险的武器。
因为一旦放开 Bash,AI 就能:
- 跑测试
- 装依赖
- 删文件
- 改 Git
- 连网络
- 调脚本
所以 Bash 规则一定要精细。
规则方式:前缀匹配
这是重点中的重点。
例如:
"Bash(go:test:*)"
表示允许:
go testgo test ./...go test -run xxx
但要注意
Tony 特别提醒:
Bash 规则是前缀匹配,不是 glob,不是 regex。
这意味着你不能把它当通配正则来理解。
也意味着一些你以为限制住的模式,可能被变种参数绕过。
结论
对于需要极其严格控制的场景:
- 不能只依赖 Bash 前缀规则
- 还要靠沙箱
- 或者改用更专门的工具控制网络等能力
十六、WebFetch 和 MCP 权限
WebFetch and MCP Permissions
除了文件和 Bash,这一讲还提醒了另一种风险:
外部连接风险
WebFetch
可以按域名授权。
例如:
- 放行官方文档域名
- 拒绝未知站点
这是控制 AI 获取外部内容的重要手段。
MCP
可以按服务器或工具授权。
例如:
- 允许整个 GitHub MCP
- 对 Jira 的建单操作改成 ask
特别注意
Tony 提醒:
MCP 权限规则不支持
*通配。
想允许某个服务器所有工具,要直接写服务器名。
十七、权限体系的本质总结
Essence of the Permission System
到这里,可以把 permissions 总结为:
一套“AI 工具调用立法系统”
它不是模糊的“给不给权限”,而是非常细颗粒度地规定:
- 哪种工具
- 哪种文件
- 哪个命令前缀
- 哪个网站域名
- 哪个 MCP 服务
分别:
- 允许
- 询问
- 禁止
十八、第二大支柱:沙箱机制
Pillar Two: Sandboxing
Tony 提出一个非常关键的问题:
既然权限体系已经这么细了,为什么还要沙箱?
答案是:
权限体系防已知规则内的问题,沙箱防未知漏洞和规则绕过。
学霸理解
权限体系像:
- 法律
- 审批制度
沙箱像:
- 防弹玻璃
- 隔离病房
- 操作系统级围栏
即使法律失效了,围栏还在。
十九、沙箱依赖什么?
What Does the Sandbox Depend On?
在 Ubuntu / Debian 上,Claude Code 的沙箱需要两个基础工具:
bubblewrap(bwrap)socat
各自作用
bwrap
核心沙箱工具。
利用 Linux namespace 创建隔离环境。
socat
负责沙箱内外通信桥接,尤其在网络隔离里有用。
安装命令
sudo apt-get update && sudo apt-get install -y bubblewrap socat
macOS
依赖系统自带的 Seatbelt 框架,不需要额外安装同样工具。
二十、/sandbox 不是直接开启,而是配置入口
/sandbox Is a Configuration Entry Point
运行 /sandbox 后,你会进入交互式选择。
这里有两个关键模式需要理解。
二十一、两种沙箱模式怎么选?
How to Choose Between Sandbox Modes?
选项 2:Sandbox BashTool, with regular permissions
这是 Tony 强烈推荐的模式。
含义
- 开启沙箱
- Bash 在沙箱里跑
- 同时仍然遵守 permissions 规则
- 该 ask 的还 ask
- 不是进了沙箱就完全自动放行
适合
- 大多数项目
- 团队协作
- 有敏感代码或配置
- 想要“法律 + 监狱”双保险
选项 1:Sandbox BashTool, with auto-allow in accept edits mode
这是偏效率优先的模式。
含义
- 也开启沙箱
- 但在
acceptEdits模式下 - 某些在沙箱边界内的 Bash 会自动放行
- 减少你频繁确认的成本
适合
- 个人项目
- 非关键环境
- 对沙箱边界有足够信心
- 想更高自动化
推荐结论
生产和团队场景,优先选“沙箱 + 常规 permissions”模式。
二十二、沙箱的核心原理
Core Principle of the Sandbox
Claude Code 没走重容器路线(如 Docker),而是更多利用操作系统安全原语:
- Linux:
bubblewrap - macOS:
Seatbelt
这是更轻量、更原生的隔离方式。
本质
当沙箱启用后:
所有高风险 Bash 命令和其子进程,都被关进一个受限执行环境。
二十三、文件系统隔离:默认写限制,默认读相对开放
Filesystem Isolation: Strict Write Boundary, Relatively Open Read Access
这里有个非常重要、但容易误解的点:
1. 默认写权限:严格限制
AI 通过 Bash 的写操作,默认只能在:
当前工作目录(CWD)及其子目录
内进行。
任何试图改外部文件的行为都会被阻断,除非明确批准。
这就是“防破坏”的核心边界。
2. 默认读权限:相对开放
沙箱内对大量文件仍有只读能力。
为什么这样设计?
因为 AI 有时确实需要读取:
- 系统库
- 全局配置
- 外部依赖信息
- 其他辅助上下文
Tony 认为这是“务实”的设计。
3. 更精细的读写控制还是靠 Permissions
也就是说:
- 沙箱负责粗边界
Read/Edit/Write规则负责精细立法
二十四、网络隔离:默认拒绝,白名单通行
Network Isolation: Deny by Default, Allow via Whitelist
沙箱的网络策略非常关键。
工作方式
- 沙箱里的网络请求会被代理拦截
- 只有
WebFetch(domain:...)放行的域名可以通过 - 未知域名会暂停并请求你的许可
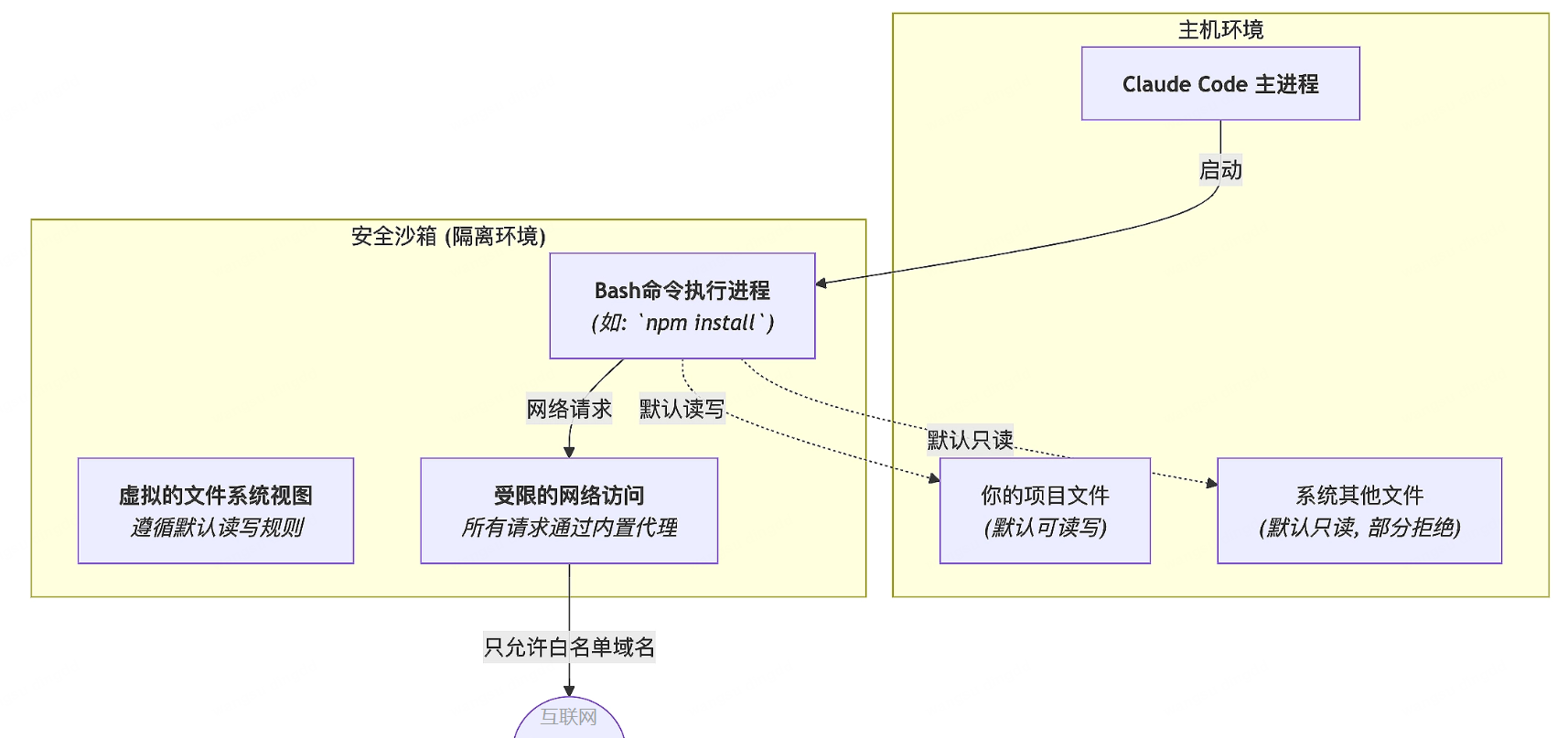
价值
这解决了非常现实的问题:
- AI 随便连外网
- 不小心把信息送到未知服务
- 执行脚本时静默下载东西
一句话
沙箱下的网络访问不再是“能上网就都能上”,而是“按域名白名单精确通行”。
二十五、“安全 YOLO 模式”是这一讲的高级思想
“Safe YOLO Mode” Is the Advanced Idea of This Lecture
这里 Tony 讲了一个非常值得记住的工程化观念:
bypassPermissions不是完全不能用,而是只能和严格沙箱搭配使用。
为什么?
因为 bypassPermissions 相当于跳过应用层审批。
如果没有沙箱,就等于:
- AI 几乎裸奔
- 没人拦它
- 风险巨大
但如果有严格沙箱:
- 写出界会被挡住
- 访问危险网络会被挡住
- 行为边界仍被 OS 层控制
于是就形成:
高自动化 + 强边界保护
适合什么任务?
- 自动修 lint
- 批量格式化
- 机械性重构
- 在限定目录内反复试错
安全 YOLO 的工作流
- 先配置严格沙箱和权限
- 再启用
--dangerously-skip-permissions - 让 AI 在“笼子里”高速工作
- 结束后再用
git diff审核成果
二十六、实战配置的设计思想
Design Logic of the Practical Configuration
Tony 给出的 Go 项目 settings.json 样例非常值得学,不是为了照抄,而是为了学会“分类治理”。
1. allow
放行无害、高频、确定性强的操作
例如:
- 读常规项目信息
go testgo buildgofmtgoimportsgolangci-lint- 官方文档网站
思想
把安全且高频的动作自动化,减少无意义审批。
2. ask
对“改变世界”的动作设红绿灯
例如:
WriteEditMultiEditgo getgo mod tidygit addgit commit
思想
改代码、改依赖、改历史,都是关键节点,要保留人工主权。
3. deny
对高危动作直接划禁区
例如:
- 读
.env - 读 SSH key
- 读
/etc/passwd rmgit push
思想
对明显高风险动作,不要犹豫,直接禁止。
4. sandbox
启用沙箱,并关闭“沙箱中自动放行 Bash”
"sandbox": {
"autoAllowBashIfSandboxed": false,
"enabled": true
}
思想
让 Bash 即使在沙箱里,也继续接受 permissions 审查。
这就是 Tony 所说的:
法律 + 监狱 双重保障
二十七、本讲真正的认知升级
The Real Cognitive Upgrade in This Lecture
这一讲最重要的升级,不是记住几个字段名,而是建立这样一种工程观:
AI 安全不是“把 AI 管死”,而是“给 AI 画清边界,让它在边界内高效工作”。
也就是说:
- 安全不是效率的敌人
- 安全是自动化能长期运行的前提
- 没有边界的 AI,不可能进入严肃工程实践
二十八、这一讲和前 8 讲的关系
How This Lecture Connects to the Previous Eight
前 8 讲在不断给 AI 加能力:
- 能看
- 能记
- 能守规范
- 能按原则
- 能复用流程
09 讲第一次系统补上:
能力的反面是风险,风险必须靠治理。
所以 09 讲是整个课程从“基础使用”进入“进阶驾驭”的分水岭。
二十九、本讲知识结构图
Knowledge Structure of This Lecture
AI 能力越来越强
↓
风险也越来越真实
↓
不能靠主观信任
↓
必须建立客观安全边界
↓
Claude Code 安全哲学:
默认不信任,逐步授权,全程监督
↓
两大支柱
├── Permissions
│ ├── 模式:宏观安全级别
│ ├── 规则:allow / ask / deny
│ ├── 文件访问控制
│ ├── Bash 前缀规则
│ ├── WebFetch / MCP 外部连接控制
│ └── /permissions 查看生效规则
└── Sandbox
├── OS 层隔离
├── 文件系统写边界
├── 网络默认拒绝
├── 白名单放行
└── 和 permissions 形成双保险
↓
最终目标
让 AI 高效但可控,自动化但不失主权
三十、学霸速记表
Quick Revision Table
| 知识点 | 结论 |
|---|---|
| AI 核心风险 | 不确定性、上下文不完整、统计随机性 |
| Claude Code 安全哲学 | 默认不信任,逐步授权,全程监督 |
| 安全第一支柱 | Permissions:应用层规则与审批 |
| 安全第二支柱 | Sandbox:OS 层隔离与边界 |
deny / allow / ask 优先级 |
deny > allow > ask / 默认行为 |
| 文件规则 | Read / Edit / Write 控制文件访问 |
| Bash 规则 | 前缀匹配,不是 glob / regex |
WebFetch |
按域名控制外部访问 |
MCP |
按服务器 / 工具控制调用 |
/permissions |
查看当前生效权限规则 |
| 沙箱文件系统特性 | 默认写受限到当前工作目录,读相对开放 |
| 沙箱网络特性 | 默认拒绝,白名单域名放行 |
| 推荐沙箱模式 | Sandboxed Bash + regular permissions |
| 安全 YOLO 模式 | bypassPermissions 只能与严格沙箱结合使用 |
三十一、学霸自检题
Self-Check Questions
基础题
- 为什么说对 AI 的信任不能建立在“它很聪明”之上?
- Claude Code 安全哲学的三个关键词是什么?
- Permissions 和 Sandbox 分别解决什么问题?
进阶题
- 为什么
deny的优先级最高? - 为什么 Bash 权限规则不能被当成正则或 glob 理解?
- 为什么沙箱里默认“写严格、读开放”是一种务实设计?
思辨题
- 如果你在团队项目里配置安全规则,哪些 Bash 命令你会直接 allow,哪些会 ask,哪些会 deny?
- 你是否会开启
autoAllowBashIfSandboxed?为什么? - 你会如何为一个 Node/React 项目设计一套兼顾效率与安全的
settings.json?
三十二、学霸总结
Top-Student Summary
这一讲是整套课程从“会用 AI”走向“能驾驭 AI”的真正起点。
因为在 AI 原生开发中,最难跨过的并不是上下文、命令、记忆,而是:
信任问题。
Tony 明确指出,AI Agent 的风险不是来自“恶意觉醒”,而是来自:
- 人类指令的模糊性
- AI 上下文视角的局限
- 大模型输出的统计随机性
因此,真正可靠的 AI 工程实践,不能依赖“相信 AI 会一直做对”,而必须依赖“即使 AI 做错,也伤害有限”的技术安全体系。
Claude Code 给出的答案是两大支柱:
第一大支柱:Permissions
它像应用层法律,基于:
- 默认最小权限
- 显式授权
- 用户主权
通过:
allowaskdeny
精确治理:
- 文件读写
- Bash 命令
- 外部网络
- MCP 调用
第二大支柱:Sandbox
它像操作系统层的监狱,通过:
- 文件系统隔离
- 当前工作目录写边界
- 网络默认拒绝
- 白名单域名放行
把高风险 Bash 操作关进一个受限环境。
两者结合形成:
法律 + 监狱
规则 + 物理边界
审批 + 隔离
这套机制让 AI 的强大能力不再意味着不可控风险,而可以变成:
边界清晰、结果可审、风险可控的工程自动化能力。
因此,本讲最核心的思想不是“限制 AI”,而是:
用清晰的边界换取真正可持续的自动化。
三十三、一句话记忆
One-Sentence Memory Hook
AI 不值得无条件信任,但可以被精确约束;Permissions 管规则,Sandbox 管边界,两者合起来,才是 AI 原生开发真正可落地的安全基石。