
📒 学霸笔记:04|环境搭建——为 Claude Code 接入国产大模型
Top Student Notes: 04 | Environment Setup — Connecting Claude Code to Chinese LLMs
课程 / Course: AI 原生开发工作流实战 / AI-Native Development Workflow in Practice
讲师 / Instructor: Tony Bai
章节 / Chapter: 04
主题 / Topic: Claude Code 安装、国产模型接入、分层配置体系、基础验证与终端优化
一、这一讲的核心目标
Core Goal of This Lecture
这一讲不是在讲理论,而是在做第一件真正“落地”的事:
搭建一套可用、低成本、高可访问性的 Claude Code AI 原生开发环境。
更具体地说,就是:
- 安装 Claude Code 客户端
- 不走官方 Anthropic 模型通道
- 改为接入国产兼容模型服务(以智谱 AI 为例)
- 学会用分层配置控制默认模型
- 做一次最小验证,确保环境真的能跑起来
二、本讲的核心思路:给“车身”换“引擎”
Core Idea: Replace the “Engine” While Keeping the “Car Body”
Tony 用了一个非常形象的比喻:
- 车身 / Car Body = Claude Code 客户端(CLI)
- 引擎 / Engine = 背后的大语言模型(LLM)
1. “车身”是什么?
Claude Code 客户端负责:
- 用户交互
- 文件系统访问
- 上下文管理
- Slash Commands
- Shell 执行
- Hook / Checkpoint / Sub-agent 等高级机制
也就是说,它负责的是 工作流层。
2. “引擎”是什么?
大模型负责:
- 理解输入
- 进行推理
- 生成文字 / 代码
- 决策输出
也就是说,它负责的是 智能推理层。
3. 为什么能替换?
因为 Claude Code 的设计本质上就是:
客户端工作流能力 与 后端模型服务 解耦
所以只要后端服务:
- API 兼容 Anthropic 风格
- 能接受 Claude Code 的请求格式
- 支持相应认证方式
那么 Claude Code 就可以“以为”自己在调用 Claude,其实背后在调用国产模型。
一句话理解
我们学的是 Claude Code 的工作流能力,而不是死绑定 Anthropic 官方模型。
三、第一步:安装 Claude Code 客户端
Step 1: Install the Claude Code Client
1. 前置要求:Node.js 18+
Claude Code 依赖 Node.js 生态,因此首先要检查 Node 版本:
node -v
要求:
- Node.js >= 18.0
如果版本太低,需要升级。
2. 推荐方式:用 nvm 安装 Node
文中给了基于 nvm 的示例。
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.3/install.sh | bash
. "$HOME/.nvm/nvm.sh"
nvm install 22
node -v
npm -v
学霸理解
这里不是必须装 Node 22,而是举例说明:
- 用 nvm 管理版本最方便
- 未来切换 Node 版本也更灵活
3. 全局安装 Claude Code
npm install -g @anthropic-ai/claude-code
执行返回:
changed 3 packages in 620ms
2 packages are looking for funding
run `npm fund` for details
npm fund
执行返回:
ops-claude-demo
安装后可用如下命令检查:
which claude
claude --version
如果能看到类似:
2.0.11 (Claude Code)
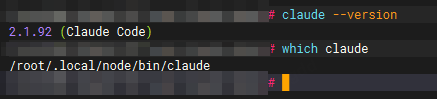
说明 Claude Code 客户端安装成功。
4. 首次运行时要注意什么?
第一次执行:
claude
Claude Code 会引导你:
- 选终端主题
- 选登录方式
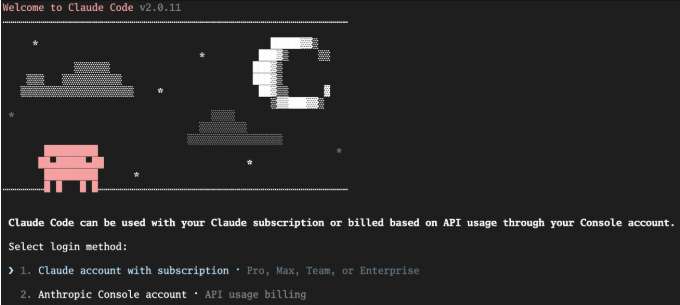
重点提醒
这一步 不要走官方浏览器登录 Anthropic 的流程,因为我们后面要自己接国产引擎。
四、核心原理:车身与引擎分离
Core Principle: Separation of Client and Model
这是整讲最关键的认知点之一。
Claude Code 默认行为
默认情况下:
- Claude Code CLI
- 会去连 Anthropic 官方 API
- 使用 Claude 模型作为智能引擎
我们要做什么?
我们要做的是:
- 不改 Claude Code 客户端本体
- 只改它的请求目标地址和认证令牌
- 让所有请求转发给国产兼容模型服务
也就是:
保留原车身,替换动力系统
这个架构图可以这样理解
你 / Your Prompt
↓
Claude Code CLI(车身 / workflow layer)
↓
Anthropic-compatible API endpoint(可替换)
↓
国产模型(新引擎 / inference layer)
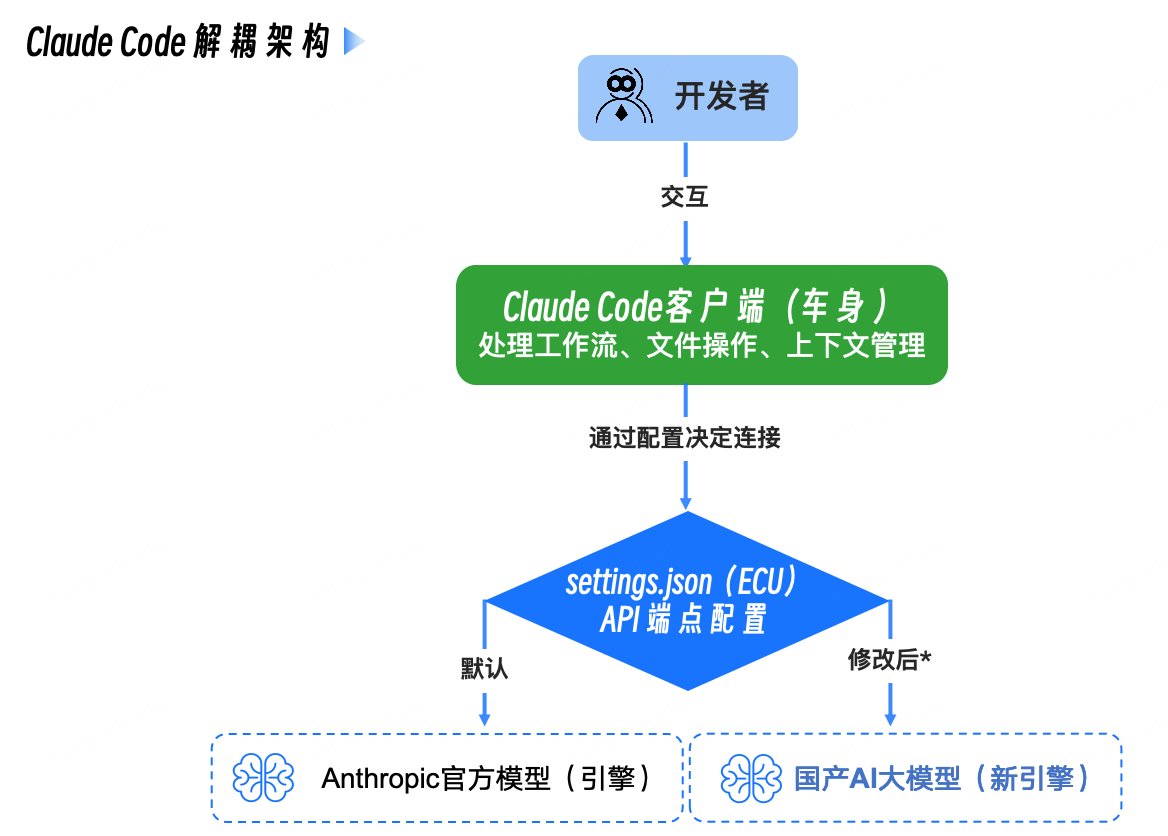
五、第二步:获取国产模型 API Key
Step 2: Obtain a Chinese Model API Key
文中以 智谱 AI 为例。
原因有三:
- 对 CLI Coding Agent 生态支持较好
- 提供兼容 Anthropic API 的接入方式
- 成本和可访问性更适合国内开发者
获取步骤
- 访问智谱 AI 开放平台
- 注册并登录
- 进入 API 密钥管理页面
- 创建新的 API Key
- 妥善保管,不要泄露
安全原则
API Key:
- 不要写进 Git 仓库
- 不要硬编码进项目源码
- 最好通过环境变量或安全配置管理
六、第三步:通过环境变量完成“请求重定向”
Step 3: Redirect Requests via Environment Variables
这是“引擎移植”的关键配置。
在 shell 配置文件中加入:
export ANTHROPIC_BASE_URL="https://open.bigmodel.cn/api/anthropic"
export ANTHROPIC_AUTH_TOKEN="<your_zhipu_api_key>"
1. ANTHROPIC_BASE_URL 的作用
告诉 Claude Code:
不要访问 Anthropic 官方地址
而是把请求发到智谱 AI 的 Anthropic 兼容接口
这是 请求重定向。
2. ANTHROPIC_AUTH_TOKEN 的作用
告诉 Claude Code:
认证时使用这个 token
虽然名字里写的是 “Anthropic”,但因为 URL 已经改了,所以它实际上会被发送给智谱服务器。
这是 认证凭证替换。
3. 本质机制
Claude Code 并不知道你“换了模型”,它只是:
- 访问一个指定地址
- 带上一个指定 token
- 期待得到 Anthropic 风格的响应
只要后端兼容,它就能工作。
学霸理解
这里本质不是“破解”或“魔改”Claude Code,而是:
利用其本来就支持的 API 可配置机制完成模型后端替换。
七、第四步:启动 Claude Code 并检查连接是否成功
Step 4: Start Claude Code and Verify Connection
设置好环境变量后,在项目目录中执行:
claude
此时如果配置成功,你会发现:
- 不再要求你用浏览器登录官方 Anthropic
- 会直接进入已登录状态
- 接着会询问你是否信任当前目录
- 进入 Claude Code 主工作界面
检查状态命令
进入后可执行:
/status
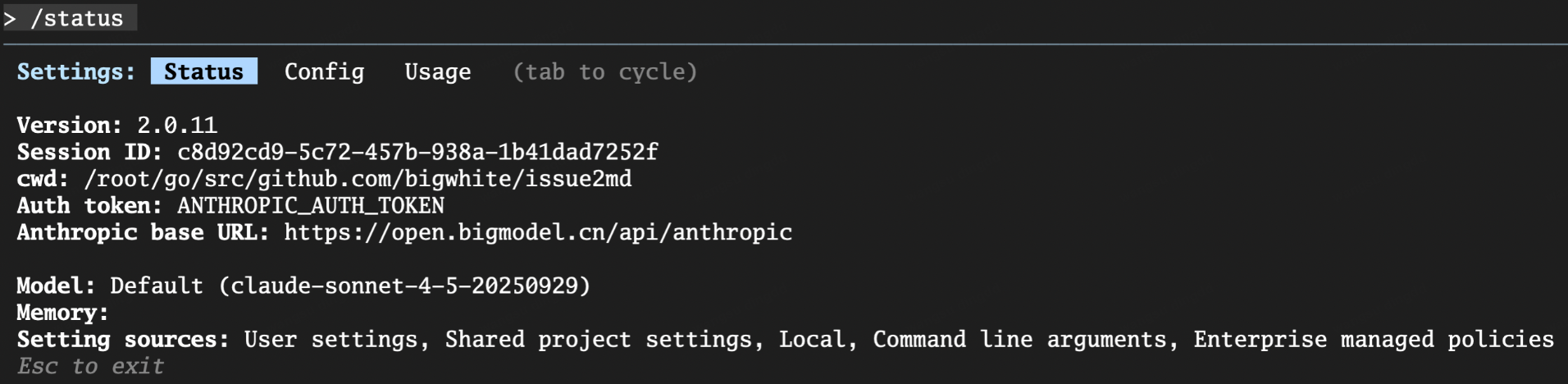
可以看到:
- 当前客户端信息
- 当前模型名字
- 运行状态等
但这里有一个“表面现象”
一开始 /status 显示的模型可能还是类似:
claude-sonnet-4-5-20250929
为什么?
因为还没进一步显式设置“默认模型映射”。
所以接下来我们要通过 settings.json,把 Claude Code 的默认模型档位映射到智谱模型上。
八、第五步:理解 Claude Code 的分层配置体系
Step 5: Understand Claude Code’s Layered Configuration System
这是本讲另一个非常重要的知识点。
Tony 强调:
Claude Code 不是只有一个配置文件,而是一个分层覆盖体系。
五层配置优先级(从高到低)
Five Layers of Configuration Priority
1. 企业级策略
managed-settings.json
- 由公司 IT / DevOps 下发
- 优先级最高
- 通常不可覆盖
- 用于强制安全策略和统一规范
2. 命令行参数
例如:
claude --model xxx
- 仅对当前会话有效
- 用于快速实验、临时覆盖
3. 项目级个人设置
.claude/settings.local.json
- 只对你自己在当前项目有效
- 默认被 Git 忽略
- 不和团队共享
适合:
- 个人测试模型
- 个人实验参数
- 不想提交到仓库的本地偏好
4. 项目级共享设置
.claude/settings.json
- 当前项目团队共享
- 应提交到代码仓库
- 用于项目级共识配置
适合:
- 项目统一规则
- 团队统一模型设置
- 权限策略、工具约定
5. 用户级全局设置
~/.claude/settings.json
- 你的全局个人配置
- 所有项目默认继承
- 本讲“引擎移植”的核心操作区
关键覆盖规则
高优先级配置会覆盖低优先级同名项。
即:
- 项目配置可以覆盖全局配置
- 命令行参数可以覆盖项目配置
- 企业策略可以覆盖一切
学霸理解
这个体系非常像:
- CSS 层叠覆盖
- K8s 多层配置
- 应用程序的 profile / override 机制
你未来做团队协作、项目隔离、多模型切换时,这个体系非常重要。
九、第六步:在全局配置中设置默认模型映射
Step 6: Set Default Model Mapping in Global Config
1. 打开用户级配置文件
Linux 下示例:
mkdir -p ~/.claude
code ~/.claude/settings.json
# 或者 vim ~/.claude/settings.json
2. 写入配置
{
"env": {
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.5-air",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.6",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.6"
}
}
3. 这些字段是什么意思?
Claude Code 内部通常按档位来理解模型:
- Haiku:轻量、快、便宜
- Sonnet:均衡主力
- Opus:高能力档
现在我们做的是把这些“逻辑档位”映射到智谱的实际模型名:
| Claude 档位 | 映射到智谱模型 |
|---|---|
| HAIKU | glm-4.5-air |
| SONNET | glm-4.6 |
| OPUS | glm-4.6 |
4. 修改后验证
重新启动 Claude Code,再执行:
/status
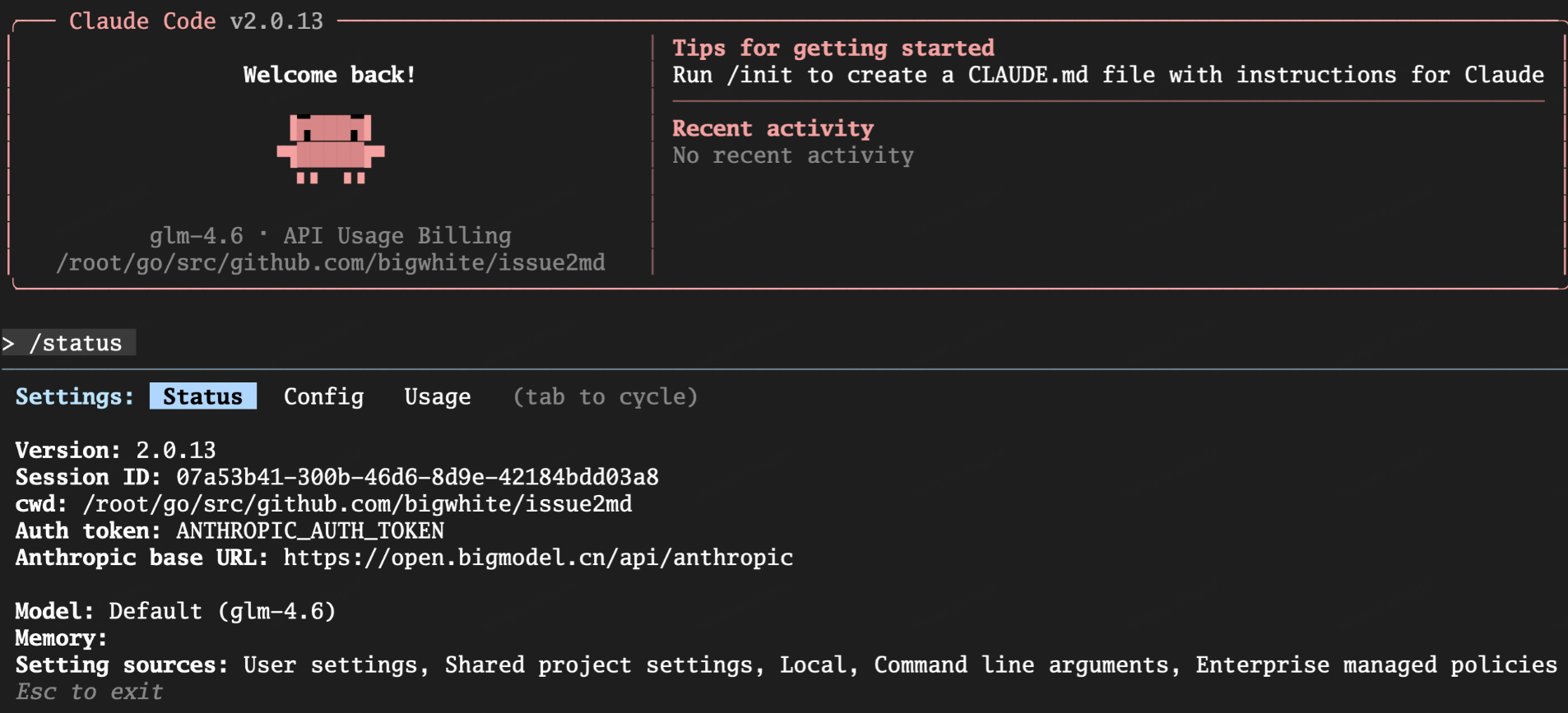
这时应能看到默认模型已经变成你映射后的模型,比如:
glm-4.6
学霸理解
这一步不是在“修改 Claude Code 的源码逻辑”,而是在告诉它:
“当你以为自己该用 Sonnet 时,实际请去调用 glm-4.6。”
这就是一种 逻辑模型层 → 实际模型层 的映射。
十、第七步:用 Headless 模式做最小可用验证
Step 7: Perform a Minimal Validation with Headless Mode
Tony 推荐用:
claude -p "你好,请用中文介绍一下Go语言,不要超过200字"
-p / --print 是什么?
这是 Claude Code 的 Headless 模式。
特点:
- 不进入交互式会话
- 直接执行 prompt
- 直接打印结果
- 很适合脚本化和快速验证
为什么这是一个好验证方法?
因为它能最小成本确认三件事:
- Claude Code 客户端能正常启动
- 后端模型连接成功
- 请求-响应链路通畅
如果你看到了正常回复,就说明:
你的“车身 + 国产引擎”组合已经真正跑起来了。
十一、终端体验优化:三个小技巧
Terminal Experience Optimization: Three Useful Tips
环境搭好只是第一步,真正高频使用时,体验也很重要。
1. Theme(主题)
可以通过:
/config
进入配置界面,选择适合终端配色的主题。
价值
- 降低视觉疲劳
- 提升阅读舒适度
- 保持工作流一致性
2. 解决多行输入难题:/terminal-setup
如果你使用:
- iTerm2
- VS Code 集成终端
可以执行:
/terminal-setup
它可以配置:
Shift+Enter换行
价值
不必再为在终端里写多行 prompt / 多段说明而痛苦。
3. 任务完成提醒
如果你使用:
tmuxscreen
可以开启活动监控,例如 tmux 的 monitor-activity on。
价值
长任务跑完时会提醒你,不必一直切换查看。
十二、本讲最重要的实践链条
The Most Important Practical Chain in This Lecture
安装 Claude Code CLI
→ 获取国产模型 API Key
→ 设置 ANTHROPIC_BASE_URL
→ 设置 ANTHROPIC_AUTH_TOKEN
→ 启动 Claude Code
→ 配置 settings.json 中的默认模型映射
→ 用 claude -p 做验证
→ 调整终端体验
十三、思考题的正确方向
How to Think About the Reflection Question
题目问的是:
只在
project-alpha中使用另一款国产模型,而其他地方仍用智谱。
这考察的是 分层配置覆盖。
正确思路
因为只想影响某个特定项目,而不影响全局,所以应该修改:
project-alpha/.claude/settings.json
如果只想你自己在这个项目里这样用,不想共享给团队,则可用:
project-alpha/.claude/settings.local.json
为什么不是全局配置?
因为:
- 全局配置
~/.claude/settings.json - 会影响所有项目
不符合题目要求。
可能的项目级配置示意
假设你希望在 project-alpha 中把默认模型切换到另一家兼容模型:
{
"env": {
"ANTHROPIC_BASE_URL": "https://example-compatible-provider.com/api/anthropic",
"ANTHROPIC_AUTH_TOKEN": "<your_project_alpha_token>",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "kimi-lite",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "kimi-main",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "kimi-main"
}
}
或改为 qwen 等其他兼容服务。
学霸理解
这道题本质上考你是否明白:
全局是默认值,项目级是局部覆盖。
十四、与前几讲的关系
Connection with Previous Lectures
和第 03 讲的关系
第 03 讲回答的是:
为什么选 Claude Code 作为核心载体?
这一讲则回答:
怎么把这个载体真正用起来,并降低实际使用门槛。
和第 02 讲的关系
第 02 讲讲的是 SDD 和规范驱动流程。
而这讲搭好的环境,正是后续执行:
spec.mdplan.mdtasks.md- CLI Agent 协作
的技术基础。
和后续内容的关系
接下来你会真正开始学:
@上下文注入!shell 执行- Slash Commands
- 自动化工作流协作
所以这一讲本质上是:
从“认知准备”切换到“实操平台搭建”的分水岭。
十五、学霸速记表
Quick Revision Table
| 知识点 | 结论 |
|---|---|
| Claude Code 是什么? | 工作流层客户端(车身) |
| 大模型是什么? | 推理层引擎(引擎) |
| 为什么能换国产模型? | 客户端与模型服务解耦,API 可重定向 |
| 安装前提 | Node.js >= 18 |
| 安装命令 | npm install -g @anthropic-ai/claude-code |
| 重定向地址变量 | ANTHROPIC_BASE_URL |
| 认证令牌变量 | ANTHROPIC_AUTH_TOKEN |
| 全局配置文件 | ~/.claude/settings.json |
| 项目共享配置 | .claude/settings.json |
| 项目个人配置 | .claude/settings.local.json |
| 快速验证命令 | claude -p "..." |
| 检查状态命令 | /status |
十六、学霸自检题
Self-Check Questions
基础题
- 什么是 Claude Code 的“车身”,什么是“引擎”?
ANTHROPIC_BASE_URL和ANTHROPIC_AUTH_TOKEN分别起什么作用?- 为什么要用
claude -p做验证?
进阶题
- Claude Code 的五层配置优先级分别是什么?
- 为什么模型默认档位(Haiku/Sonnet/Opus)需要显式映射到国产模型名?
- 如果一个项目要覆盖全局模型设置,应该改哪个配置文件?
思辨题
- 如果你们团队未来同时接入两家兼容模型服务,你会如何设计“全局默认 + 项目覆盖 + 个人试验”的配置策略?
- 如果某个项目对安全要求极高,哪些配置应该放到企业级、项目级、个人级?
十七、学霸总结
Top-Student Summary
本讲完成了从“方法论”到“工程环境”的第一次真正落地。
核心思想是:Claude Code 的客户端工作流能力(车身)与后端模型服务(引擎)是解耦的,因此我们可以保留 Claude Code 强大的工作流框架,只替换底层模型服务为国产兼容模型,从而同时获得:
- Claude Code 的工程化工作流能力
- 更低成本、更高可访问性的模型服务
整个实践过程分成几步:
- 安装 Claude Code CLI
- 获取智谱 AI API Key
- 通过
ANTHROPIC_BASE_URL和ANTHROPIC_AUTH_TOKEN完成请求重定向和身份替换 - 理解 Claude Code 的五层配置体系
- 在
~/.claude/settings.json中把 Claude 的逻辑模型档位映射到智谱实际模型 - 用
claude -p做最小验证 - 再通过
/config、/terminal-setup、tmux提升使用体验
这意味着你已经不只是“知道 Claude Code 是什么”,而是拥有了一套真正能工作的 AI 原生开发环境。
十八、一句话记忆
One-Sentence Memory Hook
Claude Code 的强大在于工作流车身,国产模型的优势在于成本与可达性;这一讲做的,就是把两者组装成你自己的 AI 开发战车。
十九、WSL 的 CentOS 7.6 环境**中安装 Claude Code
针对你提供的学霸笔记,要将其完全适配到 WSL 的 CentOS 7.6 环境中,核心难点在于:CentOS 7.6 默认的 GCC、glibc 和 Python 版本都太旧,无法直接安装 Node.js 18+ 和最新版的 Claude Code。
如果直接使用 nvm 安装 Node 18+,执行 claude 时必定会报错:GLIBC_2.28 not found。
因此,我们需要对笔记进行关键改造。以下是为你定制的 WSL CentOS 7.6 专属改造版(你可以直接替换原笔记中的“三、第一步”部分,并增加一个“避坑指南”):
核心改造点(重要提示!)
在 CentOS 7.6 上,绝对不能直接用 nvm 或官方源安装 Node.js。必须使用 Node.js 官方提供的预编译静态版本,因为它是自带新版 glibc 的,完美绕过 CentOS 7.6 的底层依赖限制。
三、第一步(完全改造版):在 CentOS 7.6 安装 Claude Code 客户端
1. 安装基础依赖
CentOS 7.6 精简环境可能缺少基础下载工具:
sudo yum update -y
sudo yum install -y curl wget git vim tar
2. 下载并解压 Node.js 预编译静态包(绕过 glibc 限制)
注意:千万不要使用 nvm install 22 或 yum install nodejs。我们直接下载 Linux 静态编译包(以目前最稳定的 v20.x 为例,完全满足 >= 18 的要求)。
# 进入家目录
cd ~
# 下载 Node.js v20 的预编译包(自带新版 glibc,不会报错)
wget https://unofficial-builds.nodejs.org/download/release/v20.18.1/node-v20.18.1-linux-x64-glibc-217.tar.gz
# 创建安装目录
mkdir -p ~/.local/node
# 解压到指定目录
tar -xzf node-v20.18.1-linux-x64-glibc-217.tar.gz -C ~/.local/node --strip-components=1
3. 配置环境变量
将 Node.js 加入系统路径,以便能在任何位置使用 node 和 npm 命令。
# 追加环境变量到 .bashrc
echo 'export PATH=$HOME/.local/node/bin:$PATH' >> ~/.bashrc
# 使配置立即生效
source ~/.bashrc
4. 验证 Node.js 安装(关键检查点)
执行以下命令,确认版本号正确,且没有报 glibc 错误:
node -v
# 应输出: v20.18.1
npm -v
# 应正常输出 npm 版本号
5. 全局安装 Claude Code
确认 Node 环境无误后,执行安装:
npm install -g @anthropic-ai/claude-code
6. 验证 Claude Code 安装
which claude
claude --version
如果能正常输出版本号(如 2.0.11),恭喜你,最难的一关已经过了! 接下来就可以继续走原笔记的流程了。
六、第三步(环境变量配置):适配 WSL CentOS 7.6 持久化
在 WSL 的 CentOS 7.6 中,为了让环境变量永久生效,需要将 API Key 和 Base URL 写入 .bashrc。
# 使用 vim 打开环境变量文件
vim ~/.bashrc
# 在文件末尾添加以下三行内容(请替换为你自己的智谱 API Key)
export ANTHROPIC_BASE_URL="https://open.bigmodel.cn/api/anthropic"
export ANTHROPIC_AUTH_TOKEN="你的智谱API_Key"
# 保存退出后,使其生效
source ~/.bashrc
(学霸注:这里配置好后,后续的启动和 /status 检查步骤与原笔记完全一致。)
🚨 增加章节:学霸避坑指南(针对 CentOS 7.6)
如果你没有使用上述的“静态预编译包”,而是习惯性用了常规方式,你会遇到以下报错,请这样解决:
❌ 坑 1:报错 GLIBC_2.28 not found 或 GLIBC_2.28 not found
原因:CentOS 7.6 自带的 glibc 是 2.17,而 Node 18+ 要求 glibc 2.28+。
解决:严格使用上面第一步中提供的 unofficial-builds 静态编译版 Node.js 链接。不要尝试自己编译 glibc,那会直接搞崩溃你的 CentOS 系统。
❌ 坑 2:Claude Code 运行报错 Error: EACCES: permission denied
原因:在 CentOS 7.6 下,有时 npm install -g 会遇到权限问题。
解决:因为我们是把 Node 装在用户目录 ~/.local/node 下的,所以不应该加 sudo。如果已经加了 sudo 导致装到了别的目录,请执行:
# 让 npm 全局安装目录指向用户目录
npm config set prefix ~/.local/node
# 然后重新不带 sudo 安装
npm install -g @anthropic-ai/claude-code
❌ 坑 3:WSL 中遇到 /terminal-setup 失效
原因:WSL 的底层终端和原生 Linux 略有差异。
解决:在 WSL 的 CentOS 中,建议直接使用 Windows 版的 VS Code,并通过 VS Code 的 WSL Remote 插件连接到 CentOS 进行 Claude Code 的交互,体验比纯终端更好。
总结适配情况
除了安装 Node.js 的方式和依赖处理在 CentOS 7.6 下有特殊讲究外,原笔记中的:
- 车身引擎分离原理
- 环境变量重定向机制
- 五层分层配置体系(settings.json 配置方式)
- 智谱模型的映射逻辑
在 WSL CentOS 7.6 环境下 100% 完全适用,无需任何修改。