
📒 学霸笔记:18|计划与任务:将规范“编译”为 plan.md 与 tasks.md
Top Student Notes: 18 | Planning & Tasks: Compile the Spec into plan.md and tasks.md
课程 / Course: AI 原生开发工作流实战 / AI-Native Development Workflow in Practice
讲师 / Instructor: Tony Bai
章节 / Chapter: 18
主题 / Topic: 从spec.md到plan.md、tasks.md,技术方案生成、任务原子化拆解、TDD 约束、依赖关系、并行标记、人工审查
一、这一讲在解决什么问题?
What Problem Does This Lecture Solve?
上一讲我们已经完成了第一步:
把模糊想法编译成清晰的需求规范
spec.md。
但仅仅有 spec.md 还不够。
因为 spec.md 只回答了:
- 我们要做什么
- 用户需要什么
- 功能边界是什么
- 验收标准是什么
它还没有完全回答:
- 技术上怎么实现
- 各模块怎么划分
- 数据结构怎么设计
- 接口如何组织
- 开发先后顺序是什么
- 哪些任务能并行
- AI 具体应该从哪一步开始执行
所以这一讲要解决的核心问题是:
如何把高层需求规范,进一步编译成工程可执行的技术方案
plan.md和原子任务列表tasks.md。
二、本讲核心结论
Core Conclusion of This Lecture
一句话总结
18 讲的核心,是把
spec.md进一步翻译成“怎么做”的plan.md和“先做什么、后做什么”的tasks.md,从而把需求语言转成 AI 和工程团队都能直接执行的工程语言。
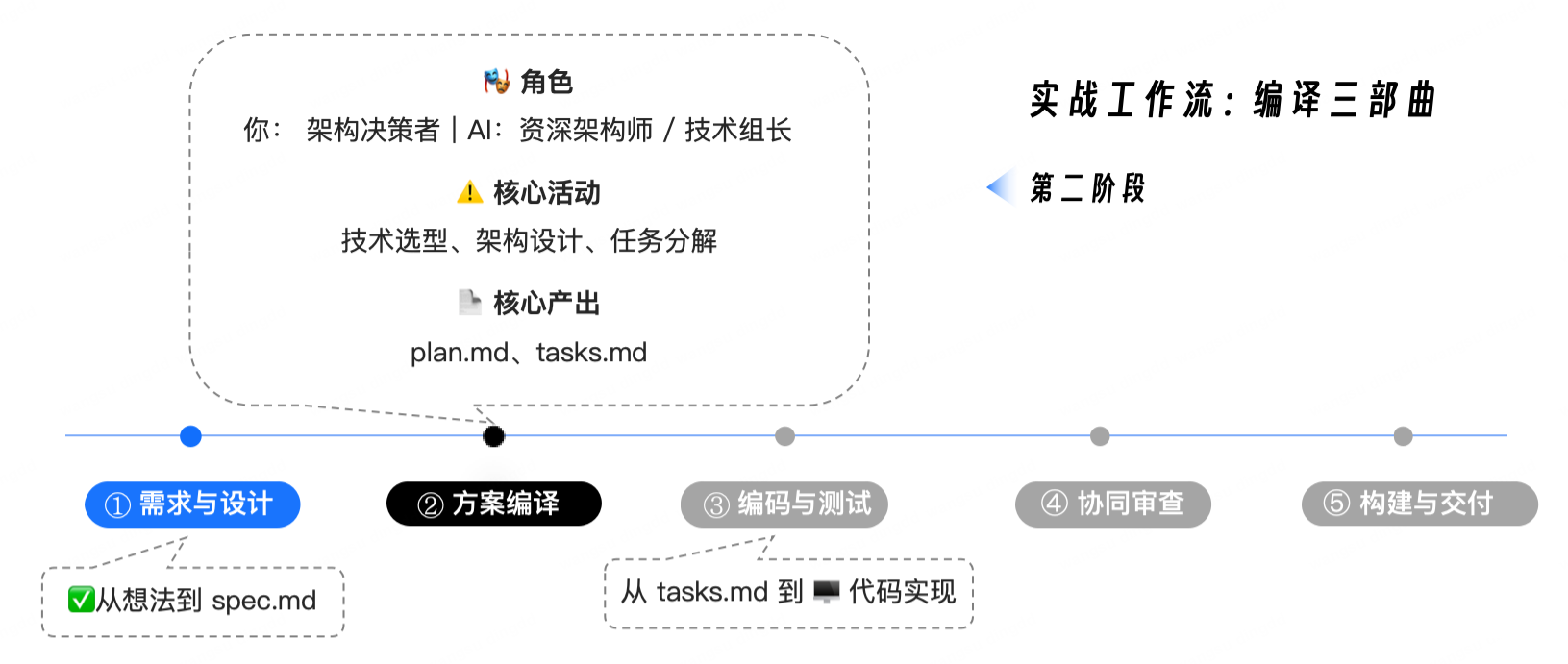
三、这一讲在“编译三部曲”中的位置
Where This Lecture Sits in the “Three-Stage Compilation Flow”
Tony 一直在讲“编译三部曲”,这一讲就是其中的第二阶段。
可以完整背成:
模糊想法
→ spec.md(需求编译)
→ plan.md(方案编译)
→ tasks.md(任务编译)
→ 编码执行
每一步分别解决什么问题?
spec.md
解决:
做什么(WHAT)
plan.md
解决:
怎么做(HOW)
tasks.md
解决:
先做什么、按什么顺序做、每一步具体做什么(ACTIONS)
学霸理解
如果说:
spec.md是建筑蓝图的需求版- 那么
plan.md就是结构施工图 tasks.md就是施工清单和工序安排表
四、为什么 spec.md 不能直接进入编码?
Why Can’t We Jump Straight from spec.md to Coding?
这是很多人容易犯的错误。
因为一旦看到 spec.md 已经很完整,就会忍不住想:
- 那直接让 AI 开始写呗
但 Tony 告诉你,这样做是危险的。
原因 1:需求不等于方案
需求描述的是:
- 用户目标
- 功能边界
- 输入输出行为
但并不天然包含:
- 模块边界
- 包职责
- 核心 struct
- 依赖方向
- 技术选型
- 测试策略
原因 2:没有方案,编码会漂
如果直接编码,AI 很可能:
- 边写边想
- 架构随手搭
- 数据结构临时拍脑袋
- 任务顺序混乱
- 测试策略不稳定
最终结果通常是:
代码看起来能跑,但整体结构不稳。
原因 3:没有任务拆解,就无法自动化执行
AI 要高效执行,需要:
- 小任务
- 明确依赖
- 清晰边界
- 顺序可控
否则“实现整个功能”这种大任务过于模糊,AI 容易失控。
五、plan.md 的本质:从 WHAT 到 HOW
The Essence of plan.md: Bridging WHAT and HOW
Tony 说得很清楚:
plan.md是连接“做什么”和“怎么做”的桥梁。
这个定位特别重要。
plan.md 不是简单技术笔记
它不是随便写一点技术想法,而是:
- 要承接
spec.md - 要符合项目
constitution.md - 要把需求翻译成可实施架构
- 要给后面的任务拆解提供依据
它解决的问题包括
- 技术上下文是什么?
- 技术栈怎么选?
- 各包职责怎么分?
- 核心数据结构怎么定义?
- 接口边界怎么划?
- 架构是否“合宪”?
- 风险在哪里?
- 交付阶段如何安排?
学霸理解
plan.md 是:
对需求的工程化解释器。
六、这一阶段你的角色变了:你是“架构决策者”
Your Role Changes Here: You Become the “Architecture Decision Maker”
上一讲你是:
需求编译器
这一讲你是什么?
架构决策者
AI 扮演什么?
资深架构师
这个角色分工很重要。
人类负责什么?
你负责:
- 给出关键技术约束
- 明确项目边界
- 确定哪些技术选型不可更改
- 决定是否符合团队哲学
- 最终审查方案
AI 负责什么?
AI 负责:
- 消化
spec.md - 根据约束展开技术方案
- 组织模块结构
- 补全接口与数据模型
- 输出完整
plan.md
学霸理解
AI 不是替你做技术决策,而是:
在你给定约束下,帮你把决策系统化展开。
七、Prompt 1 的核心作用:给 AI 设技术边界
The Core Job of Prompt 1: Set Technical Boundaries for the AI
这一讲的第一个 Prompt 非常关键。
它不是简单说“生成 plan”,而是给了 AI 一组明确的技术栈约束。
例如:
- Go >= 1.21
- Web 只能用
net/http - GitHub API 用
google/go-github+ GraphQL v4 - Markdown 尽量不用第三方库
- 初期不需要数据库
为什么这些约束重要?
因为如果不说,AI 可能会:
- 引入 Gin / Echo
- 加一堆外部依赖
- 设计数据库模式
- 用复杂库处理 Markdown
- 做出和项目哲学不一致的方案
这些都是“看似合理,但不符合项目宪法”的偏离。
学霸理解
Prompt 1 的本质不是“让 AI 开始规划”,而是:
先框定它能如何规划。
八、“合宪性审查”是这一讲最重要的亮点之一
“Constitutional Compliance Review” Is One of the Most Important Highlights
Tony 在 Prompt 1 中专门要求 AI:
逐条对照
constitution.md审查方案是否合规
这一步非常高级。
为什么这一步关键?
因为很多时候 AI 很会“写方案”,但不代表它自然会:
- 遵守简单性原则
- 遵守 TDD
- 遵守显式错误处理
- 遵守包职责内聚
- 遵守无全局变量原则
所以必须要求它做“合宪性自检”。
这一步的真正作用是什么?
它不是为了好看,而是让 AI 在生成方案时:
- 不只是想“能不能做”
- 还要想“是否符合团队哲学”
学霸理解
“合宪性审查”其实就是:
让架构设计接受项目原则的法治约束。
九、plan.md 里最该关注的五类内容
The Five Most Important Things to Review in plan.md
Tony 展示的 plan.md 很长,但你复习时要抓核心。
1. 技术上下文总结
明确:
- 语言
- 核心依赖
- 框架选择
- API 类型
- 是否有数据库
- 总体设计原则
这部分是整个方案的技术底色。
2. 合宪性审查
检查:
- 是否真的遵守简单性原则
- 是否体现 TDD
- 是否明确错误处理
- 是否保证包职责清晰
这是“方案价值观”的检查。
3. 项目结构细化
明确:
cmd/internal/parserinternal/githubinternal/converterinternal/cliinternal/config
各包干什么、怎么依赖。
这是“方案结构骨架”。
4. 核心数据结构
例如:
ResourceIssuePullRequestDiscussionReaction
这是跨模块协作的公共语言。
5. 接口设计
例如:
- GitHubClient
- Parser
- Converter
这是后续测试、实现、替换的关键边界。
十、为什么 plan.md 里要定义核心 struct 和 interface?
Why Must plan.md Define Core Structs and Interfaces?
因为从需求走向实现,中间最容易失控的就是“对象边界”。
如果没有提前定义:
- 每个包都会自己猜数据长什么样
- 传输结构会不断漂移
- 接口会越写越耦合
- 后面测试也难写
所以必须提前定义:
跨模块共享的数据模型与接口边界
学霸理解
这一步其实是在给未来代码建立“稳定连接件”。
十一、Tony 为什么强调:plan.md 生成后不要立刻相信它?
Why Does Tony Emphasize: Don’t Trust plan.md Blindly?
这是整讲最重要的工程态度之一。
Tony 特别提醒:
AI 生成的
plan.md只是待确认草稿,不是最终真理。
为什么必须人工审查?
因为 AI 虽然能生成很完整的文档,但仍然可能:
- 技术选型不符合预期
- 包划分不合理
- 合宪性只是表面敷衍
- 风险分析不准确
- 某些细节想得过度或不足
审查阶段的价值是什么?
在 plan 阶段发现问题,成本极低。
等写了几千行代码后才发现架构歪了,返工非常贵。
学霸理解
所以这一讲反复强调一个核心原则:
AI 负责生成,人工负责定夺。
十二、tasks.md 的本质:从 HOW 到 ACTIONS
The Essence of tasks.md: From HOW to ACTIONS
如果 plan.md 是施工图,
那 tasks.md 就是施工任务清单。
它不是“开发计划概述”,而是:
可直接执行的原子任务序列。
它要解决什么问题?
- 先做什么?
- 后做什么?
- 哪些任务可以并行?
- 哪些任务依赖前置完成?
- 每个任务做到什么粒度?
- 测试和实现如何交替?
学霸理解
tasks.md 其实就是:
把架构方案翻译成 AI 可执行字节码。
十三、这一阶段你的角色又变了:你是“技术组长”
Your Role Changes Again: You Become the “Technical Lead”
到了任务拆解阶段,你不再主要扮演架构决策者,而是:
技术组长
为什么?
因为这时候关心的重点从“架构合理性”转到了:
- 任务粒度
- 依赖关系
- 实施顺序
- 团队分工
- 测试优先级
而 AI 扮演的角色也变成了:
帮你把方案拆成施工步骤的执行协调者
十四、Prompt 2 的关键不是技术细节,而是执行规则
The Key to Prompt 2 Is Not Technical Details, but Execution Rules
这一讲第二个 Prompt 比第一个短得多,因为:
- 技术细节已经在
plan.md - 现在重点不是方案,而是拆解方式
Tony 强调了四个关键要求
1. 任务粒度要小
每个任务只改一个主要文件或创建一个文件
2. TDD 强制
必须先测试,再实现
3. 并行标记 [P]
无依赖任务要明确标出来
4. 阶段划分
按指定的阶段组织任务
学霸理解
Prompt 2 的本质不是:
“把 plan 写成待办事项”
而是:
把方案编译成执行图。
十五、为什么“任务原子化”这么重要?
Why Is Task Atomicity So Important?
这点非常核心。
如果任务写成:
- 实现 GitHub 获取逻辑
- 实现 Markdown 转换
- 完成 CLI
看起来很合理,但对于 AI 来说太大了。
大任务的问题
- 边界模糊
- 容易一次改很多文件
- 依赖不清
- 不易回滚
- 不易审查
- 不利于并行
- 不利于 checkpoint
- 不利于质量控制
原子任务的好处
- 一步一验
- 易追踪
- 易回滚
- 易并行
- 易交给不同 Agent
- 易做 TDD 循环
学霸理解
任务原子化,是 AI 原生开发实现自动化和可控性的前提。
十六、为什么 TDD 顺序必须写进 tasks.md?
Why Must TDD Order Be Explicitly Encoded into tasks.md?
Tony 特别强调:
constitution.md规定了测试先行,所以tasks.md必须显式体现。
这意味着 TDD 不是一种“希望大家遵守的文化”,而是:
被编码进任务编排中的硬约束。
为什么这么重要?
如果只在原则层面说“要 TDD”,但任务拆解时不体现,那么执行时很容易变成:
- 先写实现
- 最后补测试
一旦任务列表已经明确:
- 先写
parser_test.go - 再写
parser.go
那执行顺序自然会被约束住。
学霸理解
真正有效的工程规则,不是写在口号里,而是:
写进执行序列里。
十七、[P] 并行标记为什么很有战略价值?
Why Is the [P] Parallel Marker Strategically Important?
Tony 最后把它当成思考题,其实说明这是一个非常值得深入思考的点。
表面作用
标出:
- 哪些任务彼此无依赖
- 哪些可以同时进行
更深的工程价值
1. 适合多人协作
一个团队里不同成员可以并行领取任务。
2. 适合多 Agent 协作
未来多个 Subagents 可以并行执行各自任务。
3. 适合 CI 分片执行
可以把可并行任务拆进多个 job。
4. 适合资源调度
任务不再只是列表,而是具备 DAG(有向依赖图)特征。
5. 适合自动化工作编排
未来完全可以由 AI Orchestrator 自动分发 [P] 任务给不同执行单元。
学霸理解
[P] 不只是一个小标签,它其实是:
把任务列表向“可调度执行图”升级的起点。
十八、Tony 展示的 tasks.md 为什么“细得夸张”?
Why Is Tony’s tasks.md So Extremely Detailed?
AI 生成了 180+ 个任务,看起来很夸张。
但 Tony 想传达的是:
AI 时代的任务拆解粒度,可以比传统人工项目管理细得多。
过去为什么不会拆这么细?
因为人工拆这么细很费劲,维护成本高。
现在为什么可以拆这么细?
因为 AI:
- 拆任务很快
- 生成结构化文档很快
- 可以随时重排
- 可以按依赖自动分析
- 可以按规则检查 TDD 顺序
所以细粒度任务在 AI 原生开发里不再是负担,而是一种优势。
学霸理解
细任务不是形式主义,而是为了:
- 更可控
- 更自动化
- 更利于多 Agent
十九、审查 tasks.md 时你应该重点看什么?
What Should You Focus on When Reviewing tasks.md?
Tony 也特别强调 tasks.md 要审查,但不是让你逐行死盯。
重点看三类东西
1. TDD 顺序
是不是先 test 后 code?
2. 核心逻辑是否遗漏
例如:
- Reactions 支持是否有任务
- URL 解析是否完整
- CLI 参数是否覆盖 spec
3. 依赖关系是否合理
例如:
- CLI Assembly 是否在核心逻辑之后
- Parser 是否在更上层集成之前完成
- Converter 是否在数据结构定义后开始
学霸理解
审 tasks.md 不是看“写得多不多”,而是看:
执行路径是否靠谱。
二十、这一讲再次强化了“人是指挥官,AI 是参谋长”
This Lecture Reinforces Again: Human as Commander, AI as Chief of Staff
Tony 反复强调:
你才是指挥官,AI 只是参谋长。
这个比喻非常准确。
AI 的强项
- 读文档快
- 整理信息快
- 列方案快
- 拆任务快
- 找依赖快
但最终判断必须由人负责
因为只有人才能负责:
- 业务取舍
- 架构价值判断
- 风险接受程度
- 简化与复杂化的平衡
- 是否真的符合团队长期目标
学霸理解
AI 原生开发不是把控制权交出去,而是:
把高强度整理工作交给 AI,把高价值判断留给人。
二十一、模板库为什么是进阶实践?
Why Is a Template Library an Advanced Practice?
Tony 在最后提到:
- 这次为了教学没有用模板文件
- 但团队实践中应建设
plan-template.md、tasks-template.md
这很关键。
为什么模板库有价值?
1. 保证团队产出一致性
不同人、不同 AI、不同时间生成的文档风格统一。
2. 降低 Prompt 复杂度
你不必每次都重复说明文档结构。
3. 让方法论沉淀成资产
好的 plan / tasks 样式可以被团队长期复用。
4. 便于审查
固定格式更容易发现缺项。
学霸理解
模板库就是把“如何让 AI 产出高质量计划与任务文档”的经验,沉淀为:
可复用的组织资产。
二十二、本讲和 17 讲如何串起来?
How Does This Lecture Connect to Lesson 17?
17 讲解决的是:
需求清不清楚
18 讲解决的是:
需求如何变成工程方案与执行计划
串联起来就是
17 讲:把模糊想法变成 spec.md
18 讲:把 spec.md 变成 plan.md + tasks.md
19 讲:再按 tasks.md 开始编码实现
学霸理解
17 讲是“需求编译”,
18 讲是“方案与任务编译”,
这两讲合起来才真正把开发前的准备做完整。
二十三、本讲知识结构图
Knowledge Structure of This Lecture
已有 spec.md
↓
spec 只回答 WHAT
↓
还需要 HOW 与 ACTIONS
↓
生成 plan.md
├── 技术上下文
├── 技术选型
├── 合宪性审查
├── 包职责与依赖
├── 核心数据结构
├── 接口设计
└── 风险与实施计划
↓
生成 tasks.md
├── 原子化任务
├── TDD 顺序
├── 依赖关系
├── 并行标记 [P]
└── 分阶段执行
↓
人工审查
├── 方案是否合适
├── 任务依赖是否合理
├── 是否遗漏关键功能
└── 是否真正符合宪法
↓
得到 AI 可执行的工程指令集
二十四、学霸速记表
Quick Revision Table
| 知识点 | 结论 |
|---|---|
| 这一讲的核心 | 把 spec.md 编译为 plan.md 和 tasks.md |
plan.md 解决什么 |
HOW:怎么做 |
tasks.md 解决什么 |
ACTIONS:按什么顺序一步步做 |
| 这一阶段人的角色 | 架构决策者 + 技术组长 |
| AI 的角色 | 架构师 + 任务拆解参谋 |
| Prompt 1 的重点 | 技术约束 + 合宪性要求 |
| Prompt 2 的重点 | 原子化、TDD、依赖、并行 |
plan.md 核心内容 |
技术上下文、结构、数据模型、接口、合宪性 |
tasks.md 核心内容 |
小任务、顺序、依赖、测试先行、并行标记 |
| 为什么要原子化 | 易执行、易回滚、易审查、易并行 |
为什么要 [P] |
支撑多人、多 Agent、CI 并行编排 |
| 为什么必须人工审查 | AI 生成的是草稿,不是最终决策 |
| 模板库价值 | 一致性、可复用、降低 Prompt 成本 |
二十五、学霸自检题
Self-Check Questions
基础题
spec.md、plan.md、tasks.md分别解决什么问题?- 为什么不能直接从
spec.md跳到编码? - 为什么
tasks.md中必须显式体现 TDD 顺序?
进阶题
- Prompt 1 和 Prompt 2 的核心差别是什么?
- 为什么说
[P]标记有超出单个 AI Agent 的工程价值? - 为什么任务必须尽量原子化到“一个文件一个任务”的粒度?
思辨题
- 如果你们团队真的采用多 Agent 协作,
[P]标记会如何改变任务分配方式? - 你会如何设计一套适合你团队的
plan-template.md和tasks-template.md? - 在你目前项目中,哪些任务其实也可以被重构成这种“可执行字节码式”的任务列表?
二十六、学霸总结
Top-Student Summary
这一讲完成了 AI 原生开发“编译三部曲”中的第二阶段:
把上一讲得到的需求规范 spec.md,继续编译成技术方案 plan.md 和任务清单 tasks.md。
其中,plan.md 的作用是把“做什么”翻译成“怎么做”。
它要求 AI 在明确的技术栈约束下,生成一份合宪、结构清晰、具备可实施性的工程蓝图,包括:
- 技术上下文
- 架构设计
- 包职责划分
- 核心数据结构
- 接口边界
- 风险与实施计划
而 tasks.md 的作用,则是把“怎么做”进一步翻译成“先做什么、后做什么、哪些能并行、哪些必须先测试再实现”的可执行任务序列。
Tony 特别强调任务必须足够原子化,并且严格落实 TDD 原则,使 AI 在后续编码阶段可以按清晰的依赖关系稳定推进。
这一讲最重要的思想有三点:
-
技术方案必须受项目宪法约束
所以plan.md不能只是“看起来专业”,还必须通过对constitution.md的逐条合宪性审查。 -
任务清单必须是 AI 可执行的字节码级指令集
所以tasks.md不能停留在泛泛的开发待办,而要细化为一个个原子任务,并明确测试优先、依赖顺序和并行标记。 -
人工审查仍然是不可替代的
无论是plan.md还是tasks.md,AI 生成的都只是高质量草稿,最终是否符合项目预期、架构是否合理、关键功能是否遗漏,仍需人类指挥官来拍板。
此外,[P] 并行标记也体现出 AI 原生开发和传统项目管理的不同。
它不仅有助于单个 Agent 更好理解任务关系,更为多人协作、多 Agent 执行、CI 并行编排乃至未来的自动任务调度提供了基础。
所以,18 讲真正完成的升级是:
把需求文档继续压缩、重写、拆分,直到它变成 AI 和工程团队都能直接执行的工程指令集。
这一步做得越扎实,后面的编码阶段就越高效、越稳定、越少返工。
二十七、一句话记忆
One-Sentence Memory Hook
18 讲的本质,是把
spec.md继续编译成plan.md和tasks.md,让需求从“可理解”变成“可实施、可调度、可执行”。