
📒 学霸笔记:19|编码与测试:AI 驱动的 TDD 与框架能力的协同作战
Top Student Notes: 19 | Coding & Testing: AI-Driven TDD and the Synergy of Framework Capabilities
课程 / Course: AI 原生开发工作流实战 / AI-Native Development Workflow in Practice
讲师 / Instructor: Tony Bai
章节 / Chapter: 19
主题 / Topic: 编码执行、AI 驱动 TDD、Red-Green-Refactor、自我修正、Mock Server、可测试性设计、Git Worktree 并行开发、两条实战心法
一、这一讲在解决什么问题?
What Problem Does This Lecture Solve?
前两讲我们已经完成了开发前的“编译准备”:
- 17 讲:把模糊想法编译为
spec.md - 18 讲:把
spec.md编译为plan.md和tasks.md
现在终于进入大家最兴奋的阶段:
真正开始写代码。
但 Tony 这一讲不是在教你“让 AI 自动生成一坨代码”,而是在教你:
如何在 AI 原生开发中,用 TDD 作为核心约束机制,驱动 AI 稳定、高质量地完成编码与测试。
所以这一讲要解决的核心问题是:
- AI 怎么按
tasks.md真正开工? - 如何让 AI 不乱写、不自嗨?
- 如何借助测试约束 AI 的实现行为?
- 遇到编译错误、命名冲突、外部依赖时怎么办?
- 如何让 AI 不只是“写代码机器”,而是能完成“编写—验证—修复”的闭环?
二、本讲核心结论
Core Conclusion of This Lecture
一句话总结
19 讲的核心,是用 AI 驱动 TDD,把
tasks.md里的原子任务逐步转化为真实代码,并借助测试、编译器和框架能力,把 AI 从“代码生成器”提升为“可监督的初级工程师”。
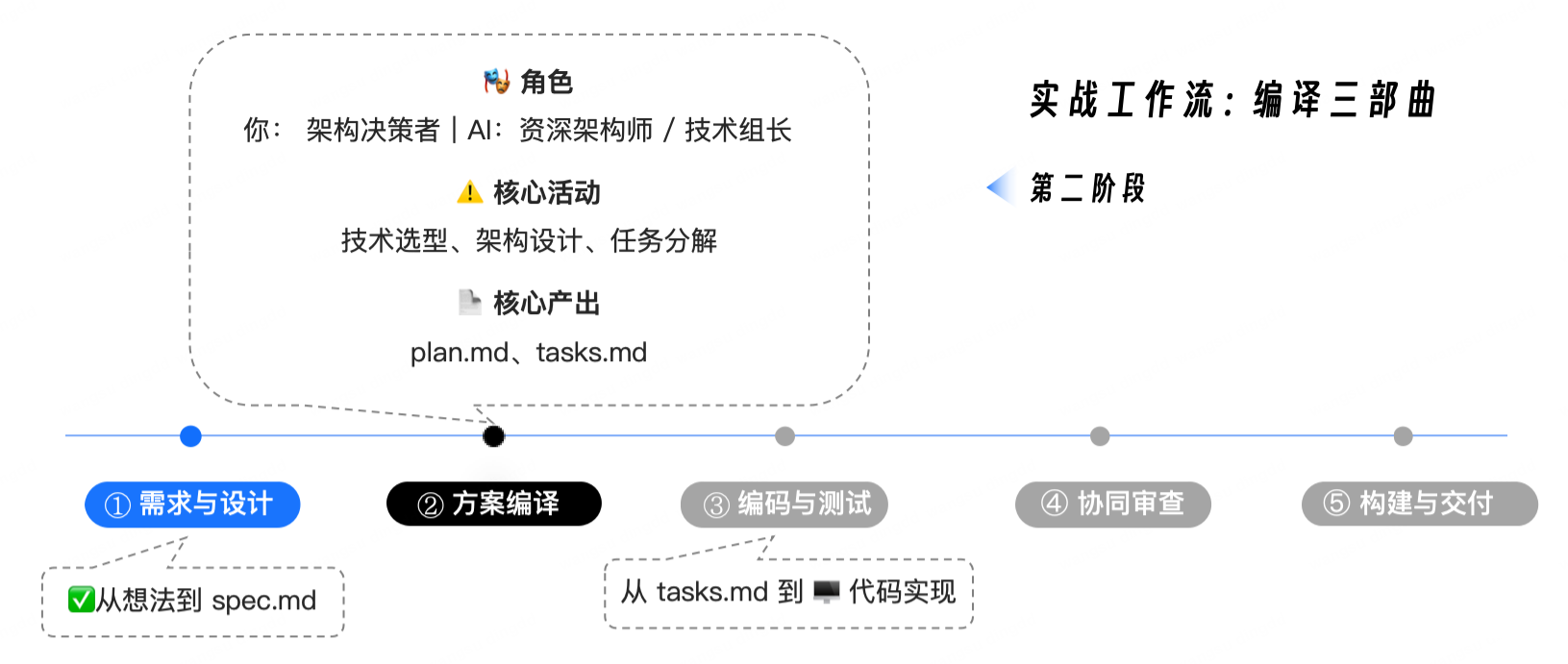
三、这一讲在“编译三部曲”中的位置
Where This Lecture Fits in the “Three-Stage Compilation Flow”
这一讲就是第三阶段:
想法
→ spec.md
→ plan.md
→ tasks.md
→ 编码与测试执行
前两讲做了什么?
17 讲
确定:
我们到底要做什么
18 讲
确定:
应该怎么做、先做什么后做什么
19 讲
真正开始:
一步步把计划落实为代码
学霸理解
如果说:
spec.md是需求蓝图plan.md是工程设计图tasks.md是施工清单
那么 19 讲就是:
正式开工施工。
四、这一讲里你的角色又变了
Your Role Changes Again in This Lecture
Tony 说得很明确:
你不再是:
- 产品经理
- 架构师
你现在是:
质量监督者 + 现场总指挥
这个角色变化非常关键。
为什么?
因为一旦进入编码阶段,最重要的事情不再是“想功能”,而是:
- 监督 AI 是否按计划做
- 监督 AI 是否遵守 TDD
- 监督 AI 是否真的通过测试
- 监督 AI 是否偏离规格或架构
- 在必要时下达修正命令
学霸理解
这一讲不是“放手让 AI 写代码”,而是:
你带着测试与任务清单,在现场指挥 AI 干活。
五、AI 原生时代,TDD 的意义发生了升级
In the AI-Native Era, the Meaning of TDD Has Been Upgraded
Tony 这一讲讲得最深刻的一点就是:
TDD 在 AI 时代,不只是测试方法,而是约束 AI 的核心机制。
经典 TDD 是什么?
传统上 TDD 的流程是:
- Red:先写失败测试
- Green:写最少代码让测试通过
- Refactor:在测试保护下重构
AI 时代为什么更需要 TDD?
因为 AI 太会“生成看起来合理的代码”了。
如果没有强约束,它很容易:
- 一次写很多
- 边写边猜
- 写得自圆其说
- 把错误逻辑也包装得很像对的
所以 TDD 变成了:
把需求转成代码化约束,再用这套约束拴住 AI。
学霸理解
在 AI 原生开发里:
- 测试不只是为了验收代码
- 测试更是为了限制 AI 的自由发挥空间
六、这一讲最核心的方法:Red-Green-Refactor 的 AI 版执行
The Core Method of This Lecture: AI-Driven Red-Green-Refactor
Tony 整讲就是围绕这个模式演练。
红 Red
让 AI 先写失败测试
本质是把需求转成可执行的验证标准
绿 Green
让 AI 只做最小实现
目标不是“写得炫”,而是“先通过测试”
重构 Refactor
在测试保护下优化结构
因为已经有回归保障,所以可以放心重构
学霸理解
AI 写代码最怕什么?
最怕“直接让它完整实现某模块”。
因为那样很容易:
- 边界失控
- 一次写太大
- 错误难发现
- 自洽幻觉严重
而 Red-Green-Refactor 把这个过程拆小了。
七、为什么 Phase 1 可以快速推进,而 Phase 2/3 要重点演练?
Why Can Phase 1 Be Fast-Tracked While Phase 2/3 Deserve Full Practice?
Tony 一开始让 AI 快速做 Phase 1:Foundation。
这是因为它主要做的是:
- 建
go.mod - 建基础目录
- 定义结构体
- 搭项目骨架
- 准备 Makefile / README / Dockerfile 等
这些工作虽然重要,但逻辑复杂度不高。
所以策略是什么?
Foundation
可以更快推进,允许 AI 一次性完成
Parser / GitHub Fetcher
逻辑复杂,有外部依赖,适合重点演练 TDD
学霸理解
不是所有任务都要一视同仁。
对于:
- 低风险、结构性工作 → 可以批量推进
- 高风险、逻辑密集工作 → 必须严格 TDD
八、Phase 1 展示了 AI 的一个关键能力:自我修正闭环
Phase 1 Showcases a Key Capability: AI’s Self-Correction Loop
Tony 在 Phase 1 里特意展示了一个很重要的现象:
AI 不是一次写完代码就结束,而是能够:
- 写代码
- 运行构建
- 发现编译错误
- 定位问题
- 自动修复
- 再次验证
为什么这点很重要?
因为这意味着 AI 的角色不再只是:
“生成初稿的打字机”
而更像是:
能读编译器反馈、做局部修复的初级工程师
这和普通代码生成器有什么区别?
普通代码生成器:
- 只吐代码
- 不会主动闭环
Claude Code 这种 AI Agent:
- 会读错误
- 会改代码
- 会重跑命令
- 会迭代修复
学霸理解
这一讲开始真正体现了“Agent”而不是“补全工具”的差异。
九、Phase 2 的本质:用 TDD 驯服纯逻辑模块
The Essence of Phase 2: Use TDD to Tame a Pure Logic Module
Tony 选择 internal/parser 作为第一个完整 TDD 实战对象非常好。
因为 URL 解析模块:
- 逻辑清晰
- 无外部依赖
- 适合做表格驱动测试
- 很适合演示 TDD 基本流程
Phase 2 的第一步:RED
Prompt 要求 AI:
- 先写
parser_test.go - 覆盖合法 URL、无效 URL、不支持类型
- 可以临时加空函数签名
- 但测试必须失败
这非常标准。
为什么必须明确“测试能编译但运行失败”?
因为 Red 阶段的目标不是乱失败,而是:
- 测试写对了
- 目标函数存在
- 只是逻辑没实现
这样后面 Green 才有清晰的通过路径。
十、AI 在 Red 阶段也会遇到真实工程问题:命名冲突
Even in the Red Phase, AI Encounters Real Engineering Problems: Naming Conflicts
这一段非常精彩。
AI 在 parser.go 中定义了一个新的 Parser 接口,结果和已有 types.go 中的 Parser 接口冲突。
它随后自动:
- 识别编译错误
- 理解冲突原因
- 重命名为
URLParser - 同步修改实现与测试引用
这说明什么?
说明 AI 真正在做的是:
- 读现有上下文
- 处理已有代码约束
- 响应编译器反馈
- 保持全局一致性
这已经不是“单点生成代码”,而是:
参与一个活的代码库。
学霸理解
真实开发中最大的难点不是从零写代码,而是:
在已有系统里不撞车。
AI 能处理这类冲突,说明它开始具备真实工程协作能力。
十一、Green 阶段的关键原则:只写能通过测试的最少代码
The Key Principle of the Green Phase: Write the Least Code Needed to Pass the Tests
Tony 在 Prompt 2 中明确要求:
- 用
strings.Split - 不要正则
- 遵守简单性原则
- 不要过度设计
- 只写能通过测试的代码
为什么这些提示很重要?
因为 AI 在 Green 阶段很容易“写多”。
例如:
- 提前支持未来 URL 格式
- 搞复杂正则
- 抽很多层
- 做一堆现在用不到的保护逻辑
这些都违反了 TDD 中 Green 阶段的精神。
Green 阶段真正的目标是什么?
不是写一个“完美解析器”,而是:
刚好让当前测试通过。
学霸理解
Green 阶段要防的,不只是“写不对”,还包括:
写过头。
十二、AI 的 Green 阶段往往也不是一次成功
AI’s Green Phase Usually Doesn’t Succeed in One Shot Either
这一讲特别真实的一点是:
Tony 没有把 AI 表现包装成“一次就对”。
在实现 Parse 时,AI 又经历了两轮修正:
问题 1:未使用 regexp
说明 AI 在思路调整后留下了旧代码痕迹
问题 2:仓库主页 URL 的错误处理不准确
说明第一次逻辑实现有边界遗漏
这很重要,因为它告诉你什么?
AI 驱动开发的真实过程应该是:
实现
→ 测试
→ 暴露问题
→ 修复
→ 再测试
而不是:
Prompt
→ 神奇一次成功
学霸理解
你要期待的不是“AI 永不犯错”,而是:
AI 能快速暴露错误并快速修复。
十三、Refactor 阶段说明:TDD 不只是验证,更是设计工具
The Refactor Phase Shows That TDD Is Not Just for Validation, but Also for Design
Tony 在 Parse 通过后,并没有停止,而是继续要求:
- 提取
splitAndValidatePath - 统一
fmt.Errorf - 重跑测试确认不破坏逻辑
这一步特别重要。
为什么?
因为很多人以为 TDD 就是:
- 写测试
- 通过
- 完事
其实不是。
TDD 的第三步 Refactor 是让你在“绿灯保护”下改善设计。
在 AI 时代这一步为什么更有价值?
因为 AI 很擅长快速重构,但前提是:
必须有测试护城河。
否则 AI 重构很容易把逻辑搞坏。
学霸理解
Refactor 阶段的真正价值是:
让代码在“先正确”的基础上再变优雅。
十四、Phase 3 难度升级:开始处理外部依赖
Phase 3 Raises the Difficulty: Start Handling External Dependencies
internal/github 和 parser 的本质差别在于:
parser是纯逻辑github依赖外部 API
这就引出了测试中的一个大问题:
单元测试不能真的去打 GitHub API。
为什么不能真打?
- 依赖网络
- 慢
- 不稳定
- 需要 Token
- 受限流影响
- 不可重复
所以必须 Mock。
十五、Mock Server 是这一讲测试进阶的关键知识点
The Mock Server Is the Key Advanced Testing Concept in This Lecture
Tony 让 AI 使用 net/http/httptest 搭建 Mock Server,这非常符合 Go 风格。
Mock Server 的作用是什么?
模拟一个假的 GitHub API:
- 返回可控 JSON
- 支持成功场景
- 支持错误场景
- 测试代码不依赖真实网络
这说明什么?
AI 不只是会写普通单元测试,还能:
- 构造测试环境
- 模拟外部依赖
- 为集成边界设计隔离层
学霸理解
这一步很重要,因为它代表:
AI 可以进入“有外部依赖的真实后端开发”场景,而不只是做纯函数练习。
十六、Phase 3 又暴露了一个真实工程问题:类型不匹配
Phase 3 Exposes Another Real Engineering Issue: Type Mismatch
AI 在测试过程中发现:
- 结构体
User.ID用的是int - GitHub API 返回的是
int64
于是它自动修改数据结构类型。
为什么这点值得注意?
因为这类问题特别真实,也特别常见:
- API 类型与本地模型不一致
- JSON 字段类型和内部结构冲突
- 转换函数丢精度风险
AI 能主动调整这一层,说明它不是机械翻译,而是具备一定的:
数据模型一致性修复能力。
十七、为了可测试性而重构,是这一讲最高级的部分之一
Refactoring for Testability Is One of the Most Advanced Parts of This Lecture
在实现 GetIssue 时,AI 发现当前设计有问题:
- 无法替换 HTTP Client
- 无法设置 BaseURL
- 无法把请求导向 Mock Server
于是它主动做了设计改进:
- 增加
NewClientWithHTTPClient - 让测试能够注入 HTTP client
- 暴露/调整内部字段便于测试
这一段最关键的意义是什么?
说明 AI 开始理解:
测试需求会反向塑造设计。
这正是 TDD 的高级价值之一。
学霸理解
TDD 不只是“先测试后实现”,而是:
通过可测试性的要求,逼出更合理的架构。
而 AI 在这里做的,不只是修代码,而是帮你改设计。
十八、这一讲说明:AI 不只是实现者,也是局部架构完善者
This Lecture Shows That AI Is Not Just an Implementer, but Also a Local Architecture Improver
在 Phase 3 里,AI 为了让测试成立,主动提升了代码结构。
这说明在实际协作中,AI 可能承担三种角色:
-
实现者
把接口和逻辑写出来 -
修复者
根据编译和测试结果修 bug -
局部设计优化者
为了可测试性或一致性,调整构造方式、依赖注入方式、字段设计
学霸理解
这就是 Tony 所说的:
AI 具备“初级工程师”潜力
它不是架构 owner,但它能在你的约束下把局部设计做得更合理。
十九、这一讲真正教你的,不是 parser 或 github 包,而是一套工作流
What This Lecture Really Teaches Is Not the Parser or GitHub Package, but a Workflow
Tony 在后面明确说了:
19 讲的目标不是交付完整工具,而是交付一套 AI 驱动的 TDD 工作流。
这句话非常重要。
这套工作流是什么?
1. 查看任务
从 tasks.md 中选择一个原子任务
2. RED
先写测试,必要时搭 Mock
3. GREEN
实现最少代码,让测试通过
4. REFACTOR
在测试保护下优化结构
5. 进入下一个任务
持续重复
学霸理解
只要你学会这一套,后面的模块都可以自己推进。
重点不是记住 Parse 怎么写,而是记住:
如何带着 AI 一步步把任务安全落地。
二十、Git Worktree 的意义:从“一个 AI”走向“多 AI 并行”
The Meaning of Git Worktree: From One AI to Multi-AI Parallel Work
这一讲后半段非常有想象力,也很实战。
Tony 提出:
- 如果
tasks.md里有[P]任务 - 那就不必顺序一个个做
- 可以利用 Git Worktree + 多 Claude 会话并行推进
这意味着什么?
一个人也可以通过多个独立工作目录:
- 同时开多个 Agent
- 各自跑不同任务
- 最后再合并结果
学霸理解
这是一种:
“一人成军”式并行开发模型
在传统开发里,并行通常意味着多人。
在 AI 原生开发里,并行越来越意味着:
一个人调度多个执行单元。
二十一、Headless + Worktree 的想象空间更大
The Combination of Headless + Worktree Unlocks Even Bigger Possibilities
Tony 进一步设想:
- 脚本解析
tasks.md - 找出
[P]任务 - 创建多个 worktree
- 后台启动多个
claude -p - 并发跑任务
- 尝试自动 merge
- 冲突时再唤起冲突解决 Agent
这说明什么?
说明 AI 原生开发的演进路径可能是:
单人 + 单 Agent
→ 单人 + 多 Agent
→ 脚本编排 + 多 Agent
→ 半自动/全自动并发开发流水线
学霸理解
这一讲不仅在教你“怎么写代码”,更在暗示:
未来开发组织形式会因为 AI 而改变。
二十二、黄金法则一:为什么一定要坚持 TDD?
Golden Rule #1: Why Must You Stick to TDD?
这是整讲最值得背的实战心法。
Tony 提出一个非常危险的误区:
既然 AI 写代码和测试都很快,为什么不让它一起生成?
听起来很高效,但风险极大。
风险是什么?
AI 最擅长“自洽”。
也就是说,它可能:
- 先写错业务逻辑
- 再写一套配合这个错误逻辑的测试
- 最后测试全绿
于是你以为没问题,实际上功能是错的。
这就是 Tony 说的:
自洽幻觉
为什么 TDD 能防这个?
因为:
- 测试先写
- 测试由人审
- 测试成为“真理边界”
- 实现只能围着测试走
学霸理解
TDD 在 AI 时代最重要的作用不是“提高设计质量”这么简单,而是:
防止 AI 自己骗自己,也顺便骗过你。
二十三、黄金法则二:永远维护“意图”的单一来源
Golden Rule #2: Always Maintain a Single Source of Intent
这条也特别重要。
Tony 说,发现 bug 后,要先判断:
- 是没想清楚?
- 还是没写对?
情况 1:意图偏差
如果是:
- 业务规则有漏洞
- 需求边界没写全
- 规格遗漏边缘情况
那么必须回去改:
spec.md
因为 spec 才是意图的唯一来源。
如果只改代码不改 spec,下次重新生成时 bug 还会回来。
情况 2:实现偏差
如果:
- spec 很清楚
- 测试也对
- 只是 AI 代码写错了
那就直接修代码,不要动 spec。
学霸理解
所以面对 bug,先问一句:
错的是想法,还是翻译?
- 错在想法 → 改 spec
- 错在翻译 → 改代码
二十四、这一讲的真正认知升级
The Real Cognitive Upgrade in This Lecture
这一讲最本质的升级,是把你对 AI 编码的理解,从:
“AI 帮我写代码”
升级成:
“我用测试、任务、编译器反馈和框架能力,监督 AI 稳定交付代码。”
这有什么不同?
前者是“工具思维”:
- 看 AI 灵不灵
- 看它一次生成得好不好
后者是“系统思维”:
- 我如何设计流程让 AI 不失控
- 我如何给 AI 约束和反馈闭环
- 我如何让代码生成变得工程化
学霸理解
19 讲真正教会你的,不是让 AI 更聪明,而是:
让 AI 的聪明变得可控。
二十五、本讲知识结构图
Knowledge Structure of This Lecture
已有 tasks.md
↓
进入编码与测试阶段
↓
人的角色变为
├── 质量监督者
└── 现场总指挥
↓
核心方法:AI 驱动 TDD
├── Red:先写失败测试
├── Green:最小实现让测试通过
└── Refactor:在测试保护下重构
↓
Phase 1
└── 快速搭基础骨架,观察 AI 自我修正能力
↓
Phase 2:Parser
├── 表格驱动测试
├── 命名冲突修复
├── 最小实现
└── 提取辅助函数重构
↓
Phase 3:GitHub Client
├── 使用 httptest Mock Server
├── 类型不匹配修复
├── 为可测试性调整设计
└── 完成外部依赖模块测试闭环
↓
进阶
├── Git Worktree 并行开发
└── Headless + 多 Agent 自动编排
↓
两条心法
├── 坚持 TDD,防止 AI 自洽幻觉
└── 维护意图单一来源:区分 spec 问题还是实现问题
二十六、学霸速记表
Quick Revision Table
| 知识点 | 结论 |
|---|---|
| 这一讲核心 | 用 AI 驱动 TDD,把任务清单转成真实代码 |
| 当前人的角色 | 质量监督者 + 现场总指挥 |
| 当前 AI 的角色 | 可监督的初级工程师 |
| AI 时代 TDD 的价值 | 不是只为测试,更是约束 AI 的行为边界 |
| Red 阶段 | 先写失败测试,把需求变成代码化规范 |
| Green 阶段 | 只写最少代码让测试通过 |
| Refactor 阶段 | 在测试保护下优化结构 |
| Phase 1 意义 | 快速搭地基,观察 AI 的自我修正闭环 |
| Phase 2 重点 | 用 TDD 驯服纯逻辑模块 |
| Phase 3 重点 | 用 Mock Server 处理外部依赖测试 |
| 可测试性设计 | 测试需求会反向推动更合理的架构 |
| Git Worktree 价值 | 一个人调度多个 AI 并行开发 |
| Headless 价值 | 可进一步进入脚本化并发开发 |
| 黄金法则一 | 坚持 TDD,防止 AI 自洽幻觉 |
| 黄金法则二 | 区分意图偏差和实现偏差,维护 spec 的唯一权威 |
二十七、学霸自检题
Self-Check Questions
基础题
- AI 时代为什么比传统开发更需要 TDD?
- Red、Green、Refactor 三步在这一讲里分别扮演什么角色?
- 为什么 Phase 3 要使用
httptestMock Server?
进阶题
- AI 在 Phase 2 和 Phase 3 中分别体现了哪些“自我修正”能力?
- 为什么说 TDD 不只是测试方法,也是设计方法?
- 为什么“先让 AI 同时生成代码和测试”是一个危险误区?
思辨题
- 如果你在真实项目中使用多 Agent + Git Worktree,你会怎样安排并行任务?
- 你如何判断一个 bug 应该回到
spec.md修,还是只修代码? - 如果项目采用 BDD 而不是 TDD,AI 工作流要怎么调整?
二十八、学霸总结
Top-Student Summary
这一讲正式进入 AI 原生开发实战中最核心的阶段:编码与测试执行。
在前两讲已经完成 spec.md、plan.md 和 tasks.md 的前提下,这一讲的任务不再是讨论需求或规划方案,而是让 AI 按照任务清单,真正把计划逐步转化为代码。
Tony 在这一讲最重要的贡献,是把 TDD 明确提升为 AI 原生开发中的“核心约束机制”。
在传统开发中,TDD 主要被看作一种测试和设计方法;而在 AI 时代,它还有一个更关键的作用:
防止 AI 在没有约束的情况下生成“自洽但错误”的实现。
因此,这一讲中的 Red-Green-Refactor 不只是开发习惯,而是一套用于约束 AI 行为的工程控制系统:
- Red:先写失败测试,把需求转化为代码化规范
- Green:只写最少实现,让测试通过
- Refactor:在测试保护下优化结构,而不破坏正确性
在具体实战中,Tony 先让 AI 快速完成 Phase 1 的基础结构定义,以此展示 AI 的“编写—构建—修复”闭环能力;随后重点演示了 Phase 2 的 URL 解析模块和 Phase 3 的 GitHub API 客户端模块。
Phase 2 说明了 AI 如何在纯逻辑模块中践行完整 TDD 流程,并在命名冲突、边界判断错误等问题中展现出真实的“自我修正”能力。
Phase 3 则进一步提高难度,引入外部依赖与 Mock Server 测试,展示 AI 如何通过 httptest 搭建模拟环境,并为了提升可测试性主动调整代码结构,例如引入可注入的 HTTP Client 和 BaseURL 配置能力。
这意味着,AI 在编码阶段扮演的不再只是一个“代码生成器”,而是一个具备以下能力的可监督执行者:
- 能根据
tasks.md逐步推进 - 能读取编译错误和测试失败信息
- 能自动做局部修复
- 能在测试要求下改进局部设计
- 能在明确约束下体现出“初级工程师”级别的执行能力
同时,Tony 也进一步打开了 AI 原生开发的想象空间:
利用 tasks.md 中的 [P] 并行标记,加上 Git Worktree 和 Headless 模式,可以让一个开发者同时调度多个 AI Agent,在不同工作树中并行完成任务,最终再统一合并。这意味着未来的开发流程,可能从“单人单 Agent”逐步演化为“单人多 Agent 编排”的新形态。
最后,这一讲最值得铭记的是两条“黄金法则”:
-
坚持 TDD,是为了防止 AI 的自洽幻觉
如果让 AI 同时生成业务代码和测试,它可能会写出一整套相互配合的错误逻辑,测试全绿却功能错误。先写并由人审查测试,才能为 AI 建立不可越过的正确性锚点。 -
永远维护意图的单一来源
当出现 bug 时,首先区分它是“没想清楚”(意图偏差)还是“没写对”(实现偏差)。- 如果是意图偏差,必须回到
spec.md修 - 如果是实现偏差,直接修代码即可
- 如果是意图偏差,必须回到
所以,19 讲真正完成的升级是:
把 AI 编码从“随机生成代码”升级为“在测试、任务和反馈闭环中被严格监督的工程执行过程”。
二十九、一句话记忆
One-Sentence Memory Hook
19 讲的本质,是用 TDD 把 AI 关进可验证的轨道里,让它从代码生成器升级为可监督的工程执行者。